I came across a post by Melanie Mitchell summarizing their recent research on understanding the capabilities of large language models (GPT in particular). LLMs seem to do relatively well at basic analogy (zero-generalization) problems, performing about 20% worse than humans in their replication study. However, the latest and supposedly best LLMs continue to fail at counterfactual tasks (which require reasoning beyond the content available in the training set), performing about 50% worse than humans. This is another study showing that the fundamental prerequisite for causal understanding is missing from the language models:
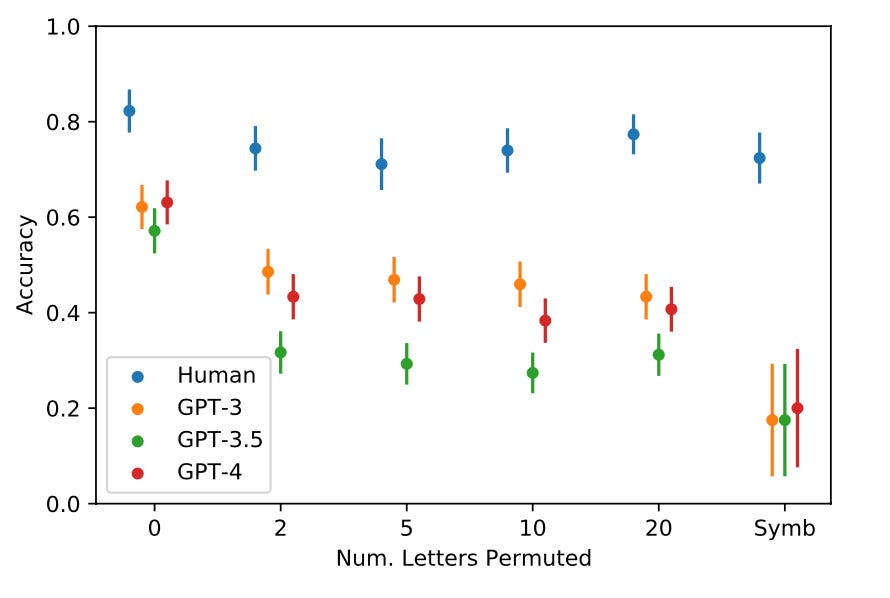
When tested on our counterfactual tasks, the accuracy of humans stays relatively high, while the accuracy of the LLMs drops substantially. The plot above shows the average accuracy of humans (blue dots, with error bars) and the accuracies of the LLMs, on problems using alphabets with different numbers of permuted letters, and on symbol alphabets (“Symb”). While LLMs do relatively well on problems with the alphabet seen in their training data, their abilities decrease dramatically on problems that use a new “fictional” alphabet. Humans, however, are able to adapt their concepts to these novel situations. Another research study, by University of Washington’s Damian Hodel and Jevin West, found similar results.
Our paper concluded with this: “These results imply that GPT models are still lacking the kind of abstract reasoning needed for human-like fluid intelligence.”
The post also refers to contradictory studies, but I agree with the comment about what counterfactual (abstract) thinking means, and thus why the results above make more sense:
I disagree that the letter-string problems with permuted alphabets “require that letters be converted into the corresponding indices.” I don’t believe that’s how humans solve them—you don’t have to figure out that, say, m is the 5th letter and p is the 16th letter to solve the problem I gave as an example above. You just have to understand general abstract concepts such as successorship and predecessorship, and what these means in the context of the permuted alphabet. Indeed, this was the point of the counterfactual tasks—to test this general abstract understanding.