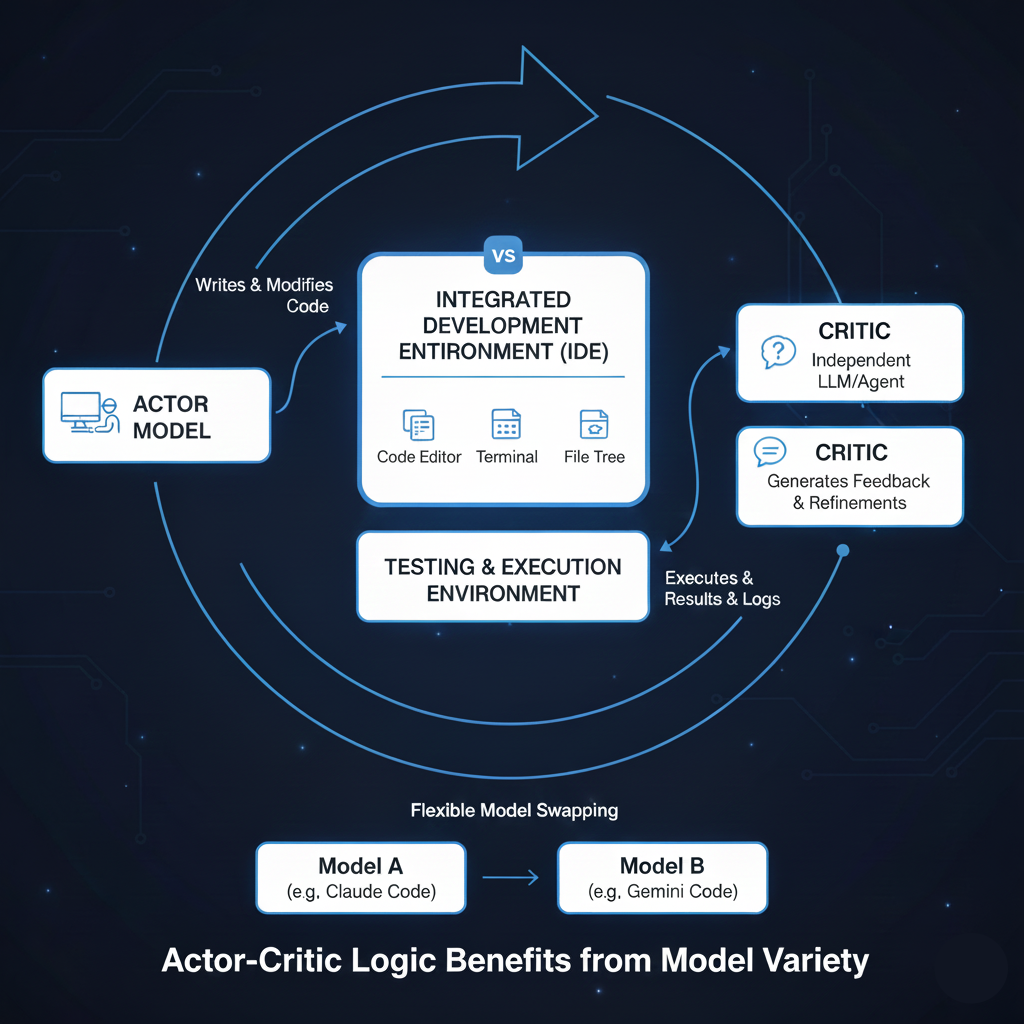
I’m not ready to go all-in on Claude Code just yet. Despite the well-earned hype, I’m sticking with Cursor (for now). That’s because model independence is worth more to me than a native tool integration in an “actor-critic” type of workspace.
I started writing this as a comment on yet another Claude Code praise, but it evolved into an end-of-year reflection on coding assistants. I’ve been hearing a lot about Claude Code, but I haven’t yet found a compelling reason to abandon Cursor, which I’ve used since near its release. For those of us with a coding background, the primary reason for starting with Cursor was the low switching cost from VS Code to Cursor.
Claude Code is Anthropic’s response to VS Code and its forks: mainly Cursor and Windsurf. By the way, a lesser-known alternative emerged from Google last month: Antigravity.1 It’s currently in public preview, so you can use it for free here. It looks promising, and the standout feature is “Agent Manager,” which essentially acts as a mission control dashboard for orchestrating multiple agents working in parallel.
I was planning to test Windsurf once my Cursor subscription expires (for the reason I highlighted here – Codemaps offer a hierarchical mental model of the codebase), but a new praise for Claude Code every day further piqued my curiosity. After checking a few resources, this comparison seemed fair (if you look past Qodo’s advertising). This one is also solid, and ultimately recommends that you “just use both.”
So, what is my plan for 2026?
I still intend to test Windsurf because I find the “Codemaps” feature intriguing. After that, I might revert to VS Code and layer in Claude Code (here is how). Meanwhile, I will keep an eye on the evolution of Google’s Antigravity, the latecomer. My hesitation to commit to a specific vendor stems from my frequent use of actor-critic logic (where one model/agent performs the task and another reviews it). I find value in using different models for these roles, so I want to retain the flexibility to switch between models. Based on the comparisons above, I might face a premium as context usage scales, but that’s a price I’m willing to pay for model independence.
And what do I mean by the actor-critic setup?
While “racing” parallel agents is becoming standard practice (see the Cursor documentation), I also use a sequential approach with diverse models: e.g., using Claude to code (the actor) and Gemini to review (the critic). VS Code documentation on agent use touches on this “multi-agent” idea without calling it an “actor-critic” setup (rightly so, as I’m just borrowing the concept from reinforcement learning).
Credit for the figure goes to Gemini 3 Flash & Nano Banana based on this reflection.