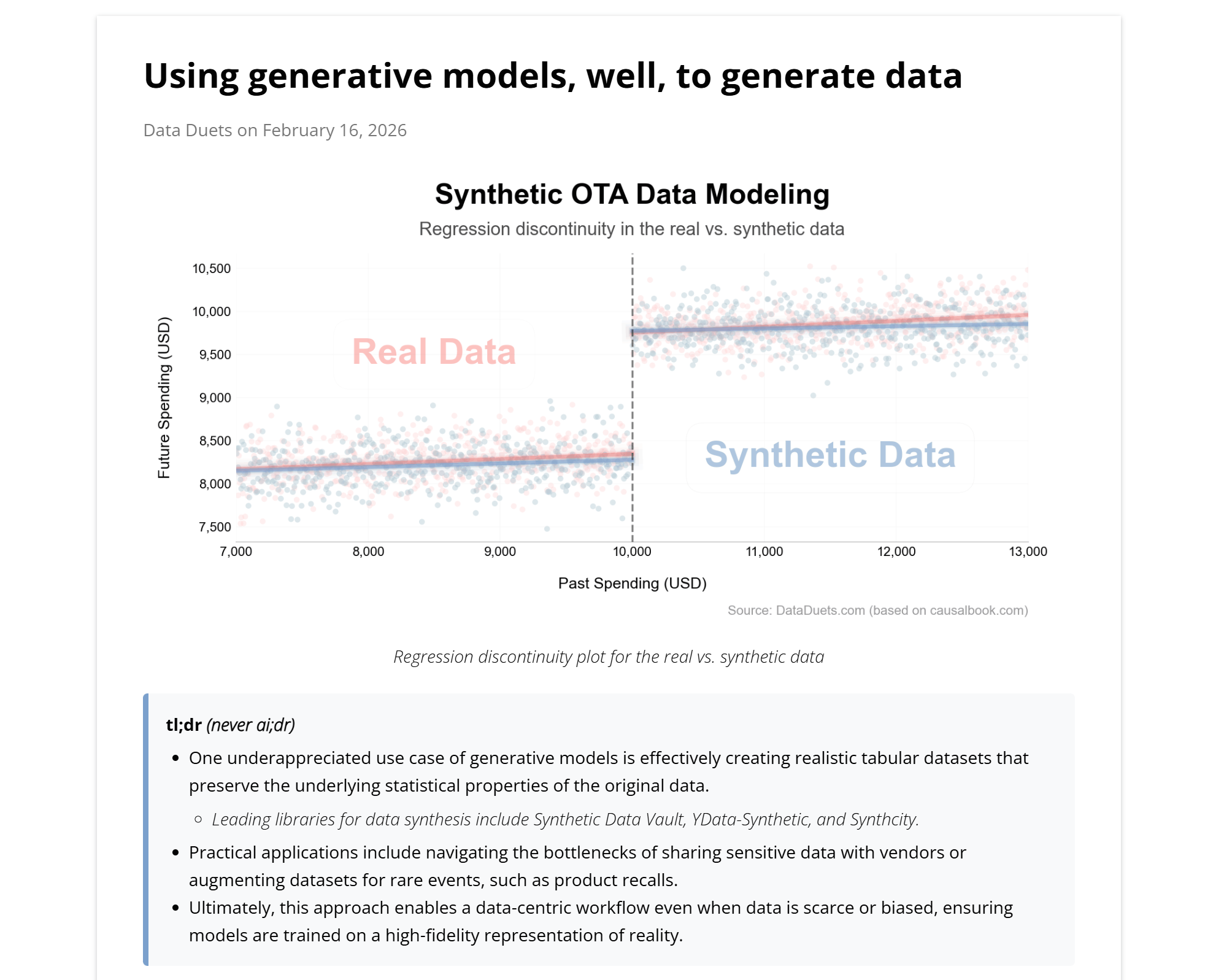
I recently shared an underappreciated use case for generative models in data science: creating high-fidelity tabular datasets (OTA data for regression discontinuity).
The model’s success in data synthesis motivated a question: what are some high-value use cases for data science teams when using generative models to create datasets? This, in turn, led to our latest Data Duets post: “Using generative models, well, to generate data”
I walk through using the Synthetic Data Vault to scale a small OTA sample while preserving its statistical properties and the causal discontinuity. Duygu Dagli then weighs in on business implications: creating statistical twins to share data with vendors for solution optimization and benchmarking, simulating product recall data, and solving cold start problems in retail.
Ultimately the approach here represents a step toward data centricity: using high-fidelity simulations to dissect and validate the assumptions that drive our models.