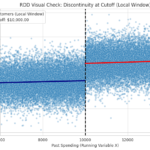
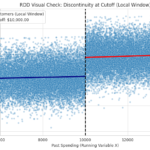
I commend Andrej Karpathy’s pedagogical work, e.g., Eureka Labs’ vision and his instructional videos. His insight that students must be proficient in AI but should be able to exist without it, is spot on. He also suggests leaning on in-class evaluation to ensure academic integrity. While a shift to in-class is clearly necessary, basing it solely on grading implications sounds too narrow.
In-class time will play a bigger role.
This is one of the reasons we have a number of recent teaching innovations in-class, including Hackathons for predictive modeling and reinforcement learning (multi-armed bandits), and LLM-assisted development deployed to HuggingFace.
LLMs can help make learning fun and engaging, starting in the classroom.
The most effective teaching fosters student ownership of learning. This involves showing that learning is fun (and surely challenging). LLMs offer an opportunity to strengthen this message. Learning is even more fun now, and somewhat less challenging: LLMs make it much easier to access material, test understanding, iterate on solutions, experiment, and get quick feedback.
That’s why we will next dedicate more of the in-class time to demonstrating how to use LLMs as life-long learning companions without mindlessly delegating our understanding. To read more about this difference, you can see the slides from my talk Mind the AI Gap: Understanding vs. Knowing here.
In all, yes, in-class time needs to be more strategically used, but making grading the sole driver represents a missed opportunity. Using more of the in-class time to model the joy of discovery and learning with LLMs (“the pleasure of finding things out”) can be a better primary driver.