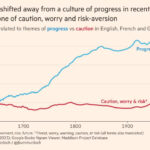
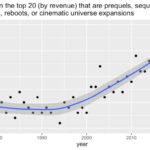
The data on education call for attention:
– 33% of eighth graders are reading at a level that is “below basic”—meaning that they struggle to follow the order of events in a passage or to even summarize its main idea.
– 40% of fourth graders are below basic in reading, the highest share since 2000.
– In 2024, the average score on the ACT, a popular college-admissions standardized test that is graded on a scale of 1 to 36, was 19.4—the worst average performance since the test was redesigned in 1990.
The article speculates on several causal links to explain the declining trend in the metrics, ranging from the effects of COVID to the influence of smartphones and social media.
The point that truly resonates with me as an educator, though, is this: a pervasive refusal to hold children to high standards. Standards are about values, not technology or tools. No tool causes the fading emphasis on rigor.
The article discusses other important aspects, such as the disparity between school districts, the heterogeneity in outcomes based on affluence, and the potential role of AI as a democratizer, but keeps returning to the same line: declining standards and low expectations. And that’s for a good reason:
“Roughly 40 percent of middle-school teachers work in schools where there are no late penalties for coursework, no zeroes for missing coursework, and unlimited redos of tests.”
This is potentially the most important problem facing our society today, and it warrants far more attention.
Source