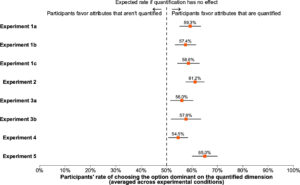
When making decisions, people are systematically biased to favor options that dominate on quantified dimensions.*
The figures show the extent of bias in different contexts. Depending on what information is quantified, our decisions change even though the information content remains about the same. In other words, quantification has a distorting effect on decision making.
This made me think about the implications for data centricity. By prioritizing quantitative over qualitative information, are we failing to stay true to the data?
The study provides some evidence: we overweight salary and benefits and overlook work-life balance and workplace culture in our decisions. We check product ratings but miss the fact that the product lacks that one little feature we really need. It’s discussed in product reviews, but not quantified.
That sounds right. Clearly, we often base our decision to stay at a hotel on the rating rather than the sentiment in the reviews. But will this tendency change? Quite possibly. We have LLMs everywhere. LLMs can help resolve the trade-off between quantification and data centricity.
Using text data for decision making is easier than ever. We can now more effectively search in product reviews instead of relying solely on ratings (e.g. Amazon Rufus). Information about work-life balance and workplace culture contained in employee reviews can be more effectively quantified. Currently, Glassdoor applies sentiment analysis to a subset of work-life balance reviews by keyword matching, but it’ll get better. Comparably.com already does better.
It’s time to do better. LLMs offer the opportunity to use qualitative information for more effective, higher quality decisions by staying true to data, or data centricity.
* From the article Does counting change what counts? Quantification fixation biases decision-making.
H/T Philip Rocco for sharing the article. You can learn more about data centricity at datacentricity.org.