“AI in 64 Pictures”
A visual journey
(Updated in July, 2025)
June, 2025
What is AI? (1/2)
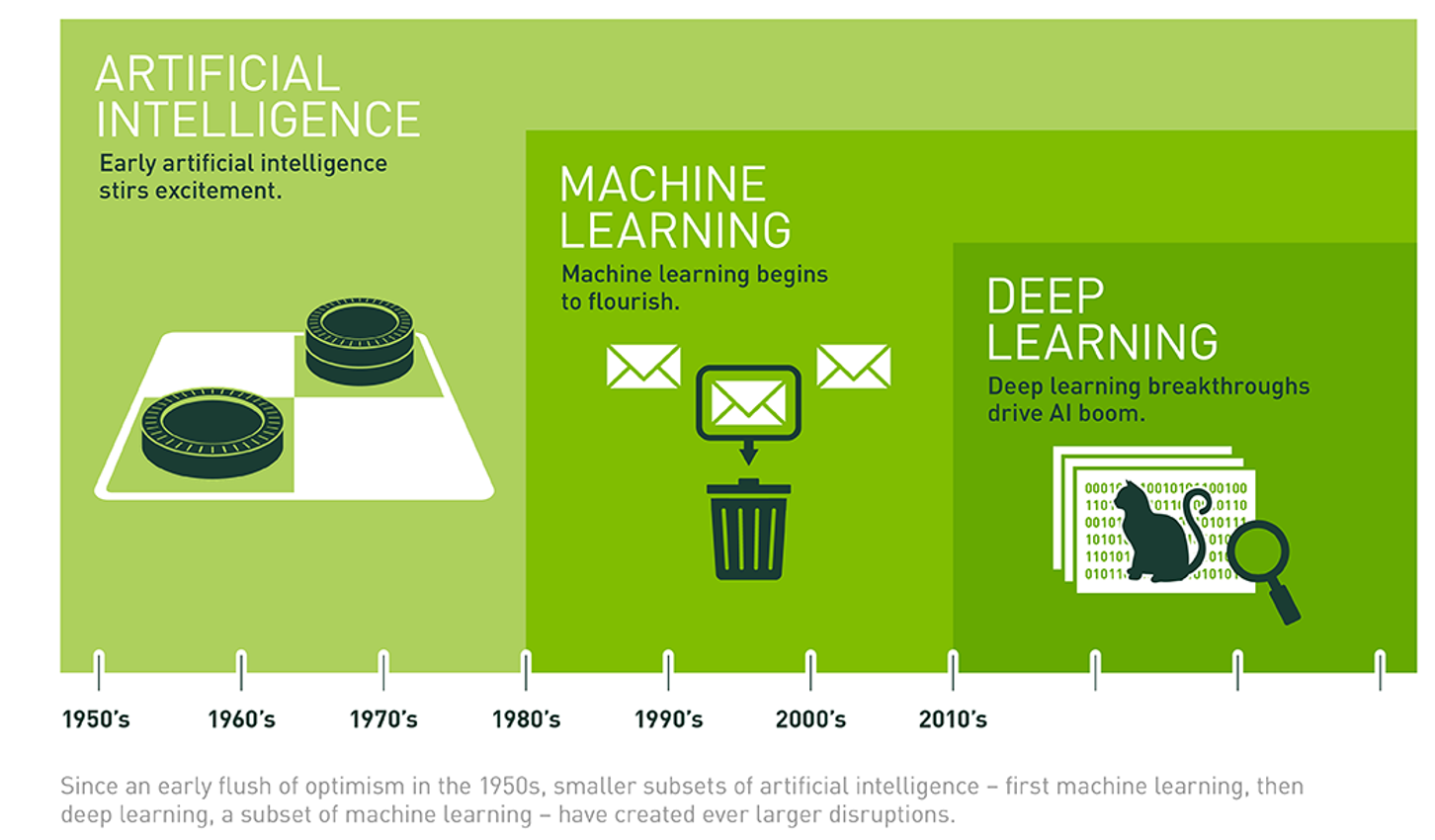
Figure 1: NVIDIA Glossary - “Machine Learning”
What is AI? (2/2)
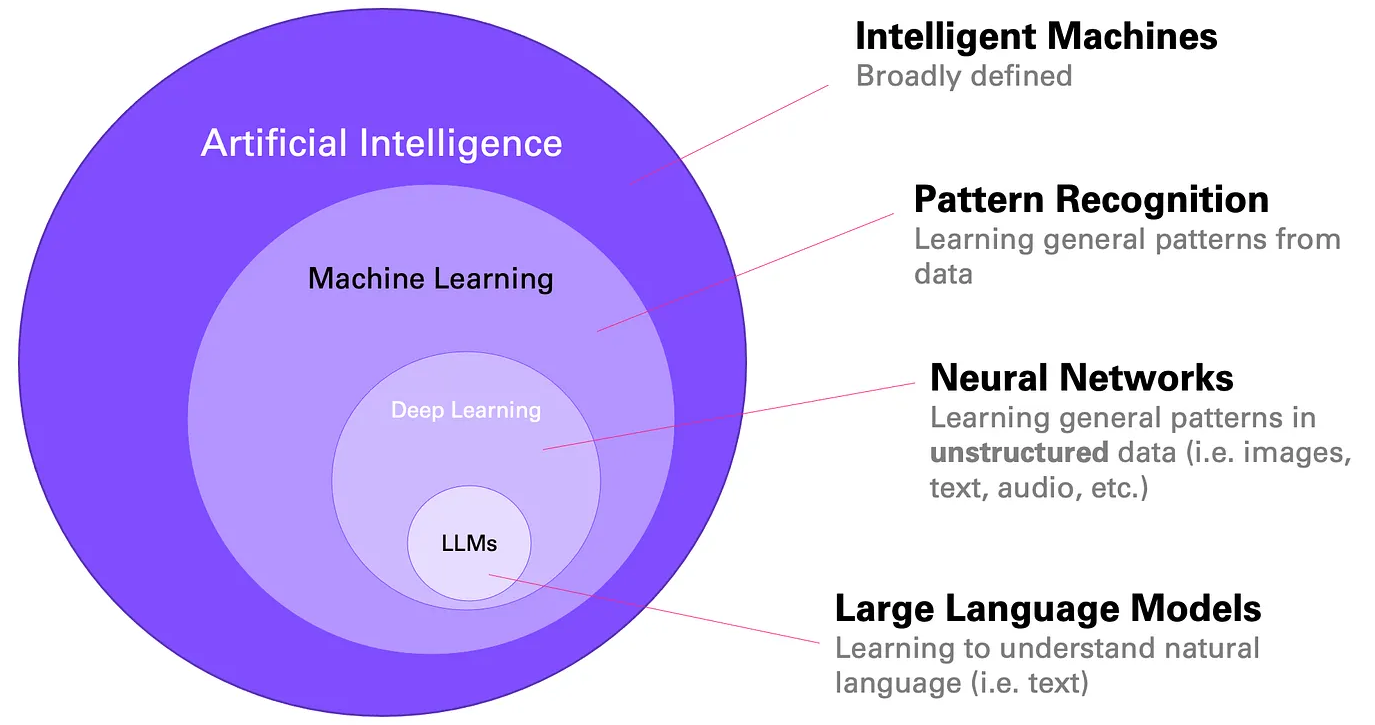
Figure 2: Microsoft Research - “How Large Language Models work”
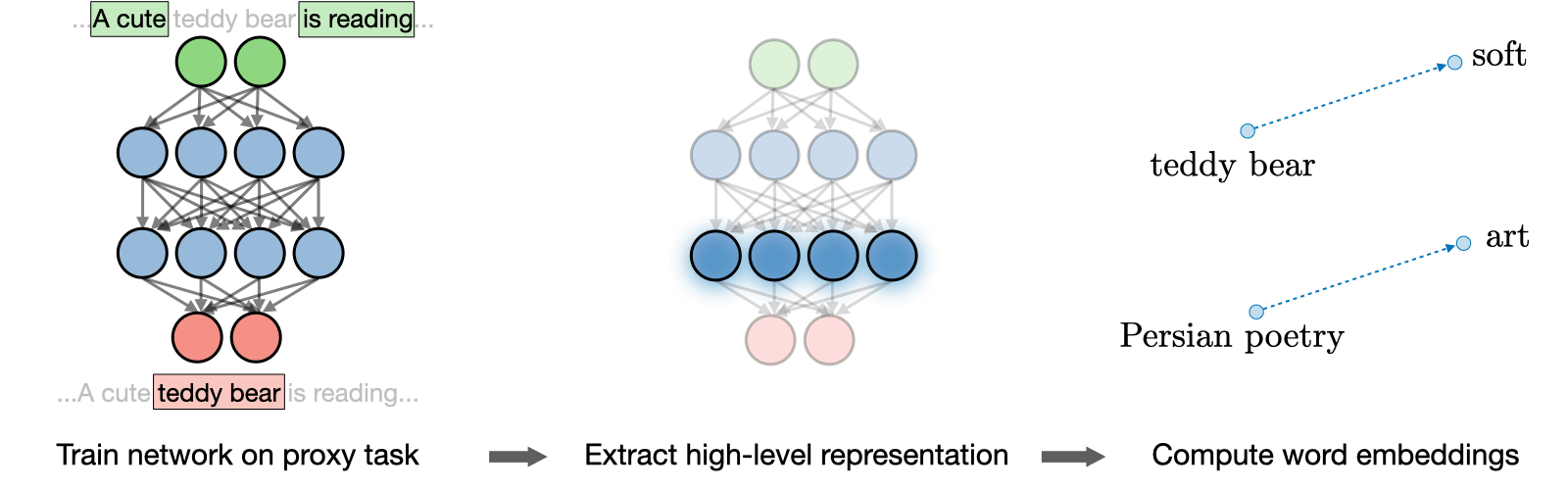
Quantification of text: Word2Vec (1/3)
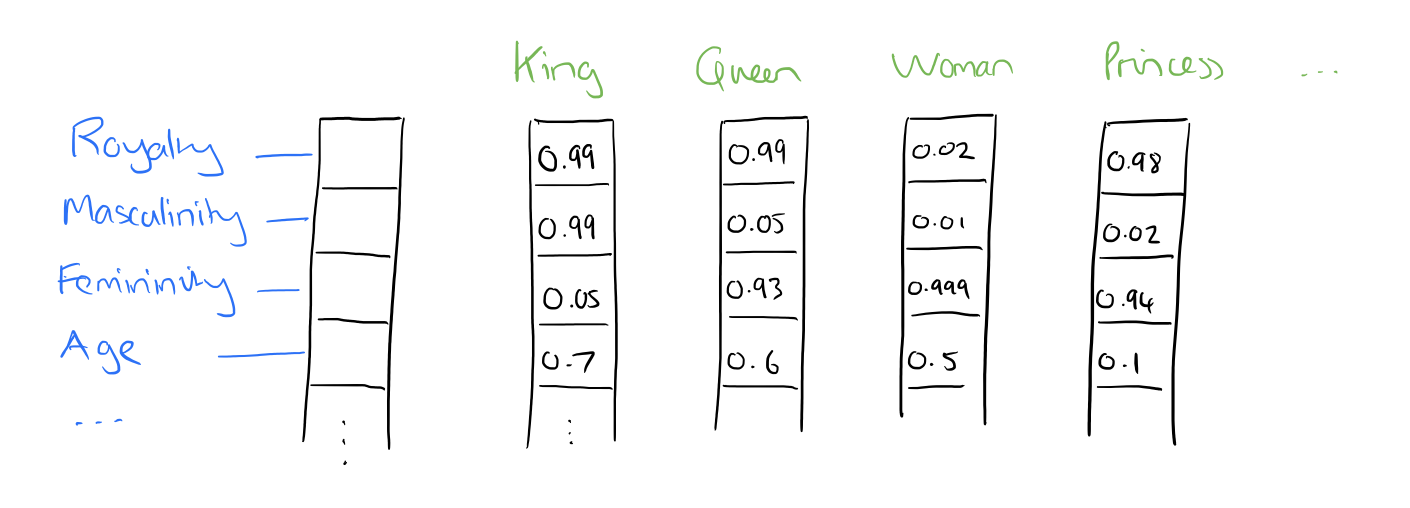

Quantification of text: Word2Vec (2/3)
Quantification of text: Word2Vec (3/3)
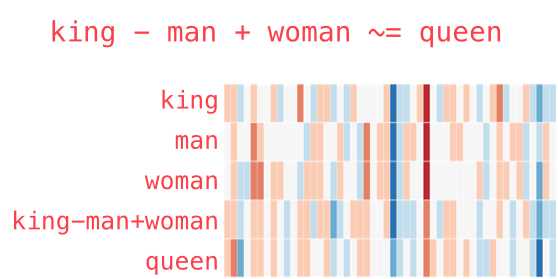
Figure 6: Jay Alammar - “The Illustrated Word2vec”
The resulting vector from “king-man+woman” doesn’t exactly equal “queen”, but “queen” is the closest word to it from the 400,000 word embeddings in this collection.
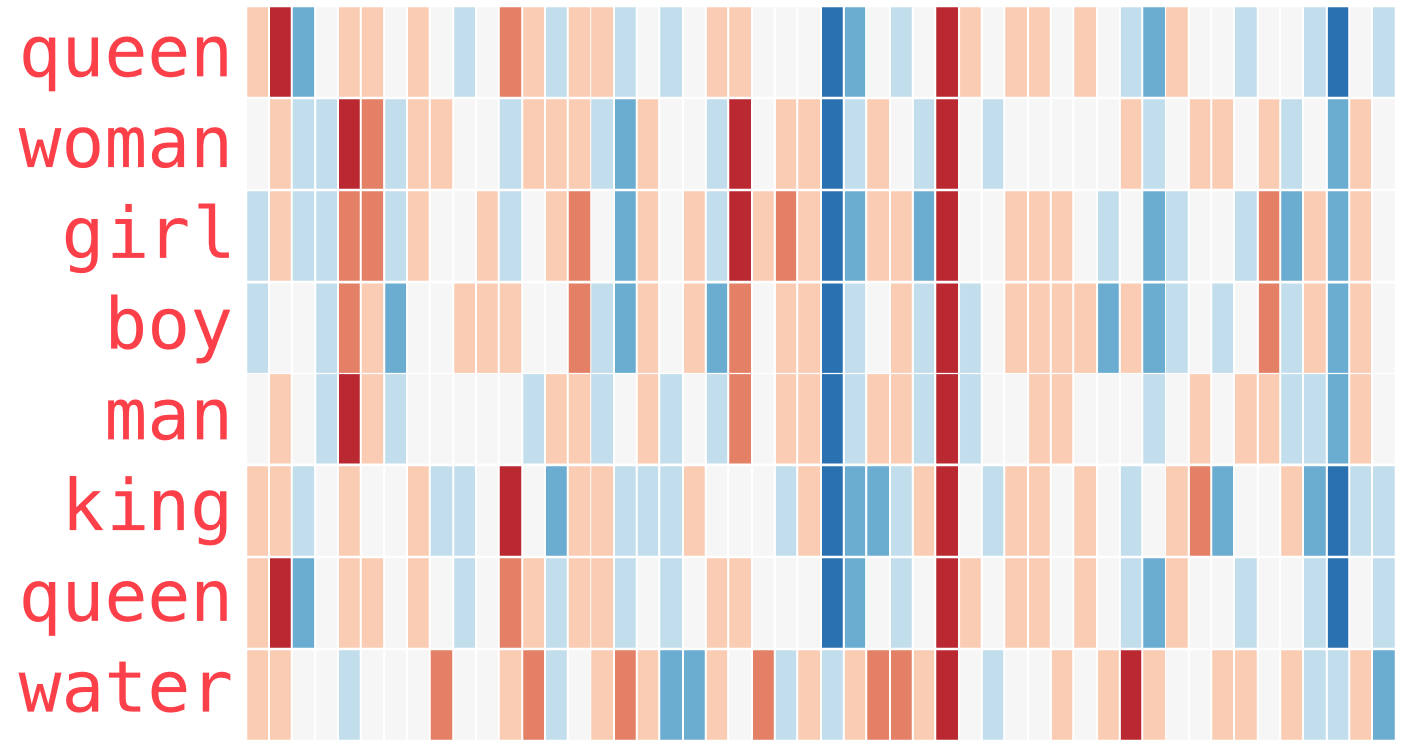
How did we quantify the text? (1/2)
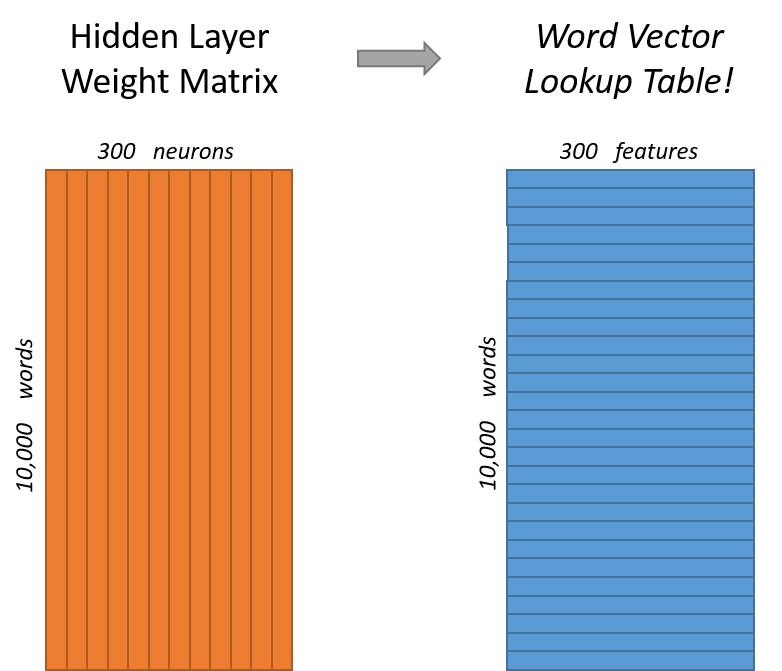
Figure 7: Chris McCormick - “Word2Vec Tutorial - The Skip-Gram Model”
How did we quantify the text? (2/2)
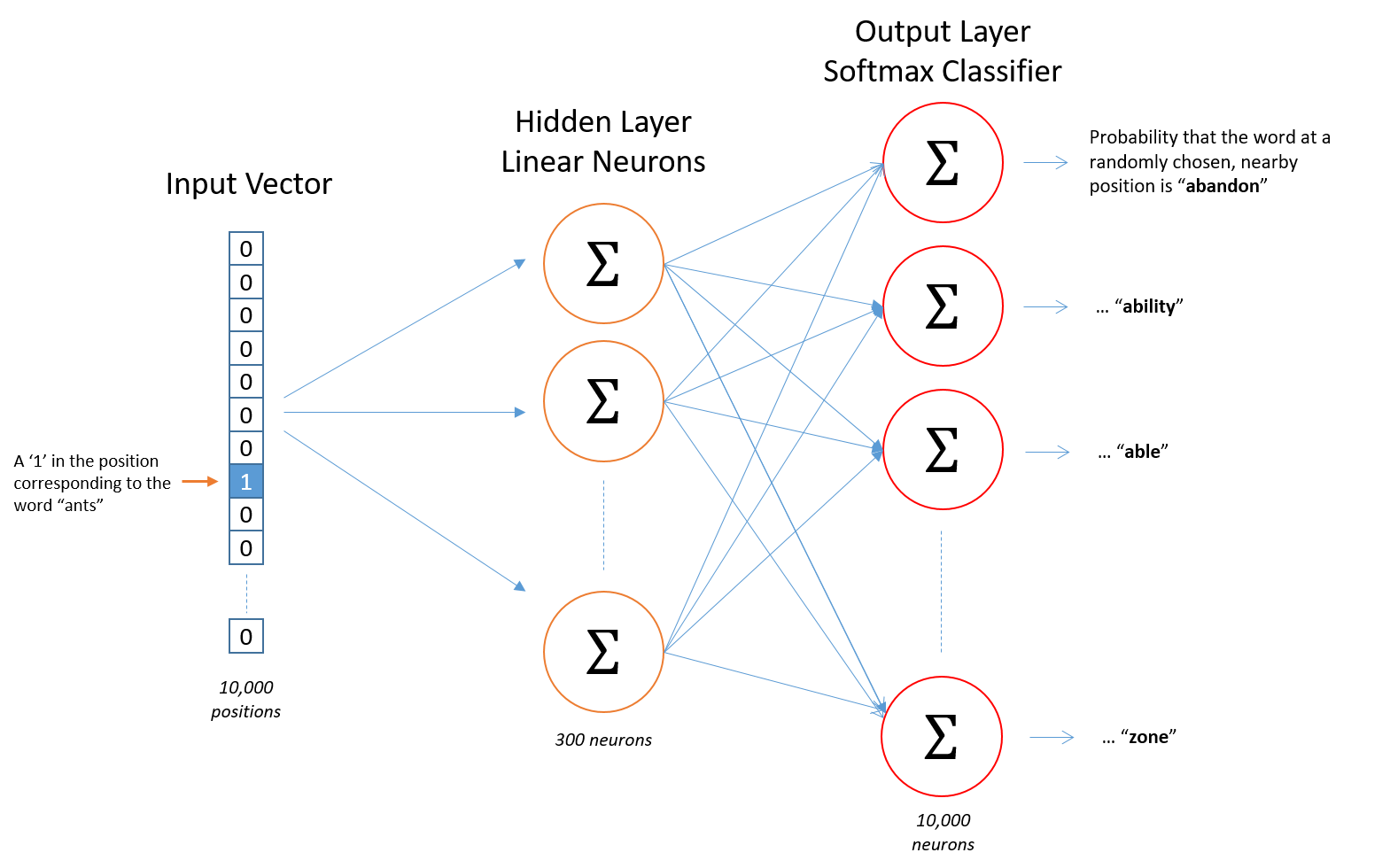
Figure 8: Chris McCormick - “Word2Vec Tutorial - The Skip-Gram Model”
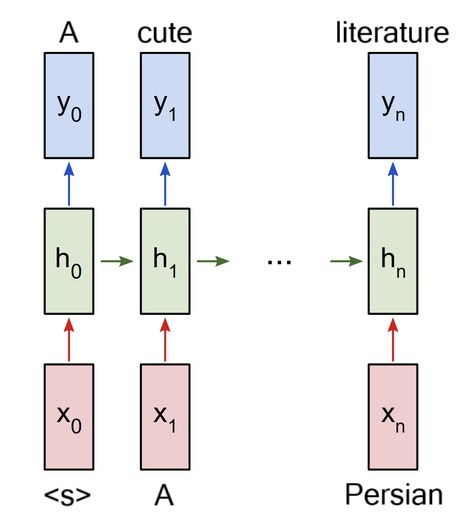
Using embeddings in RNNs (1/2)
Word vectors (embeddings) are static representations of text.
Recurrent Neural Networks (RNNs) can process sequences of embeddings to dynamically capture the context of words.
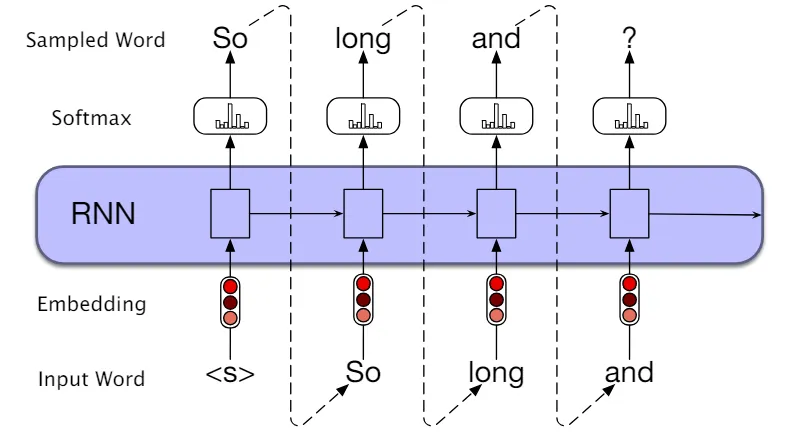
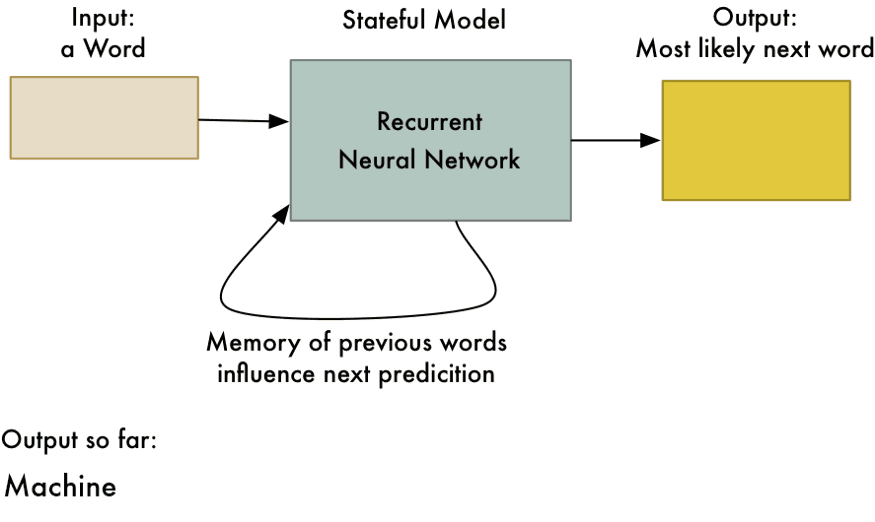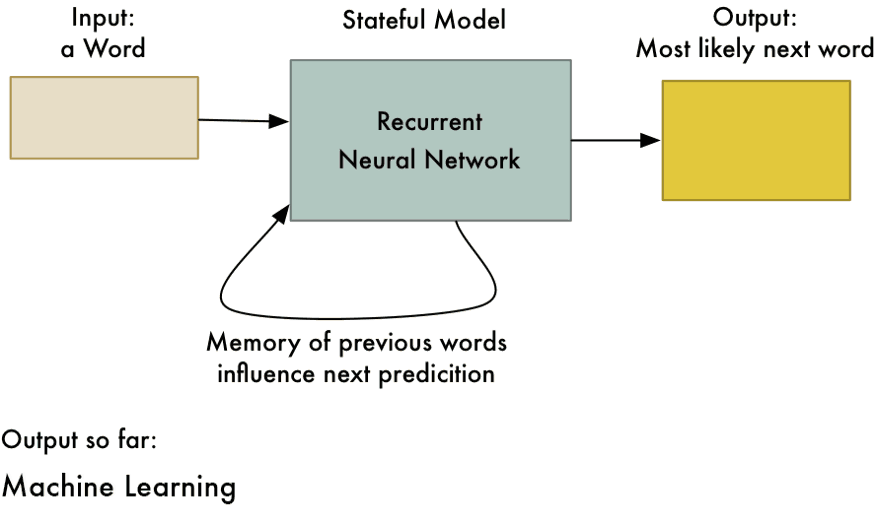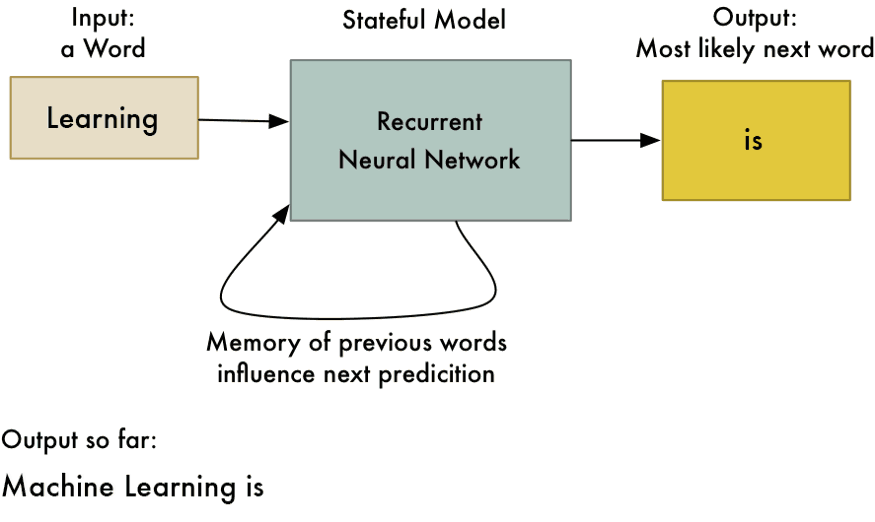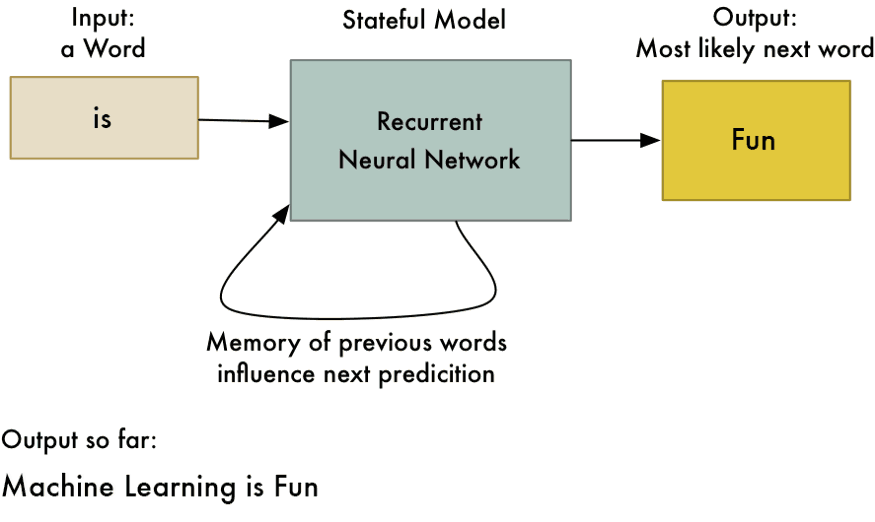
Using embeddings in RNNs (2/2)


The attention mechanism was introduced (added to the RNN decoder) to help the model focus on the relevant parts of text.

We used RNNs to dynamically process word embeddings, updating the context of the words, and paying attention.
Why is attention so important? Let’s see an application.
Adding attention to RNNs (1/2)
![]()
![]()
Adding attention to RNNs (2/2)
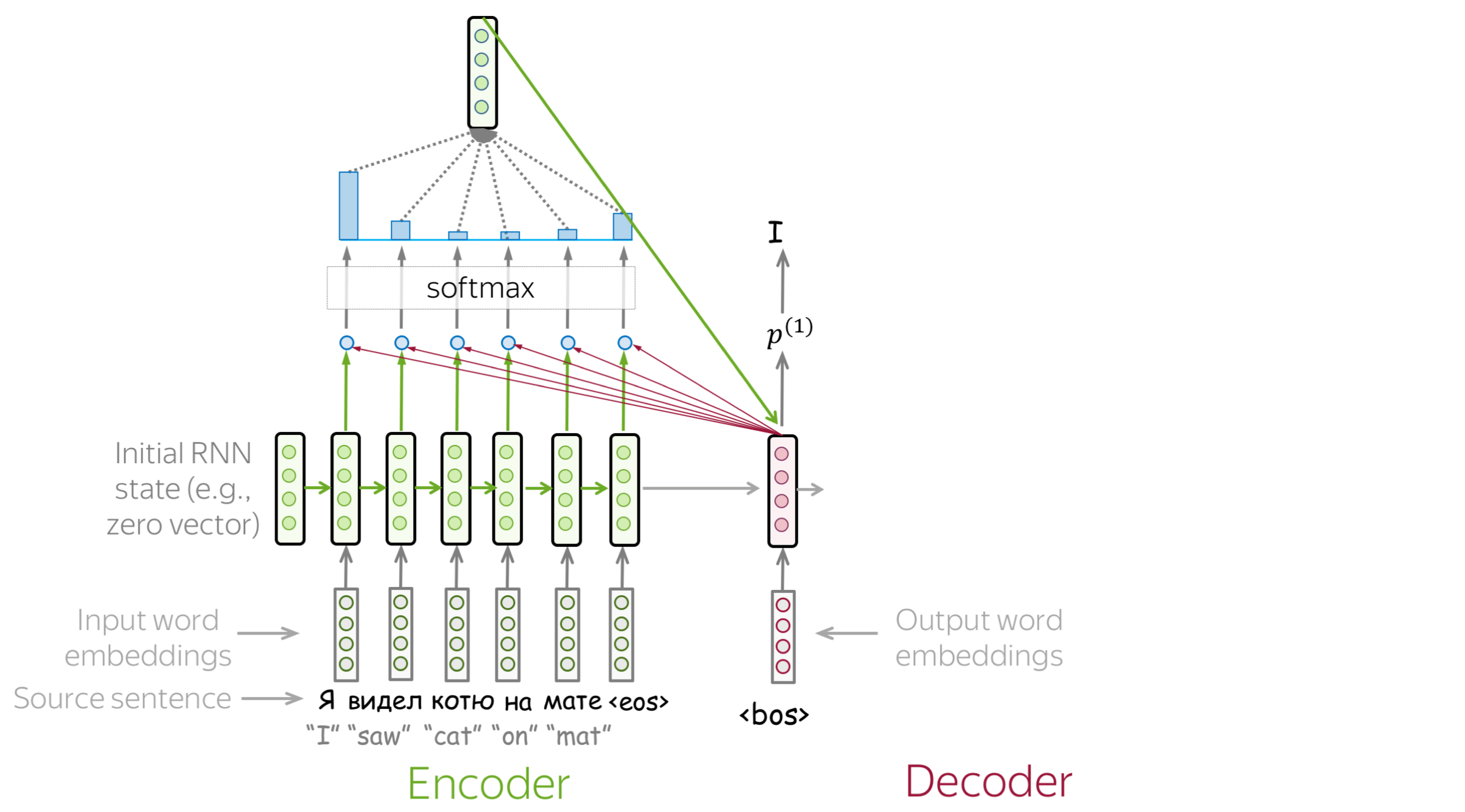
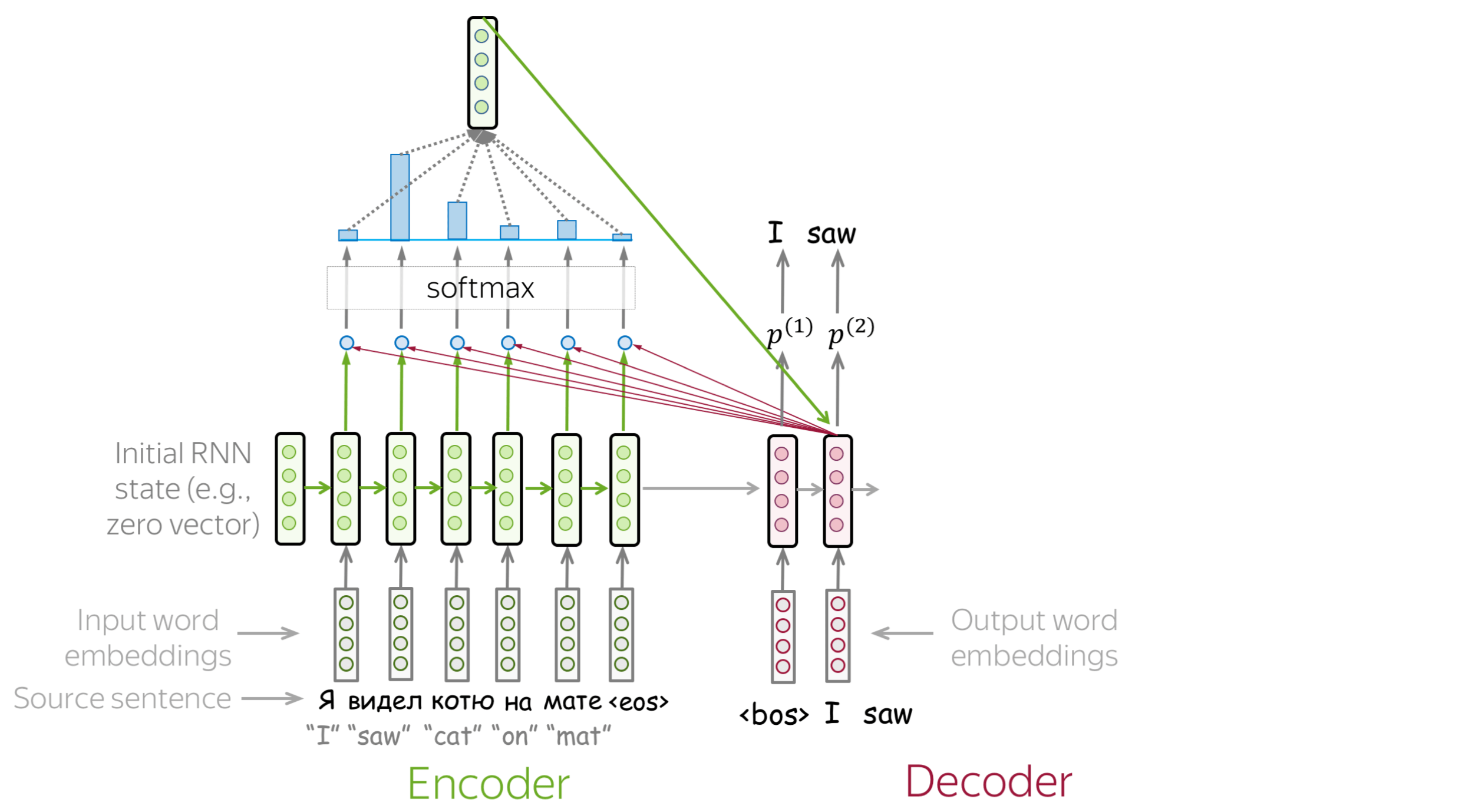
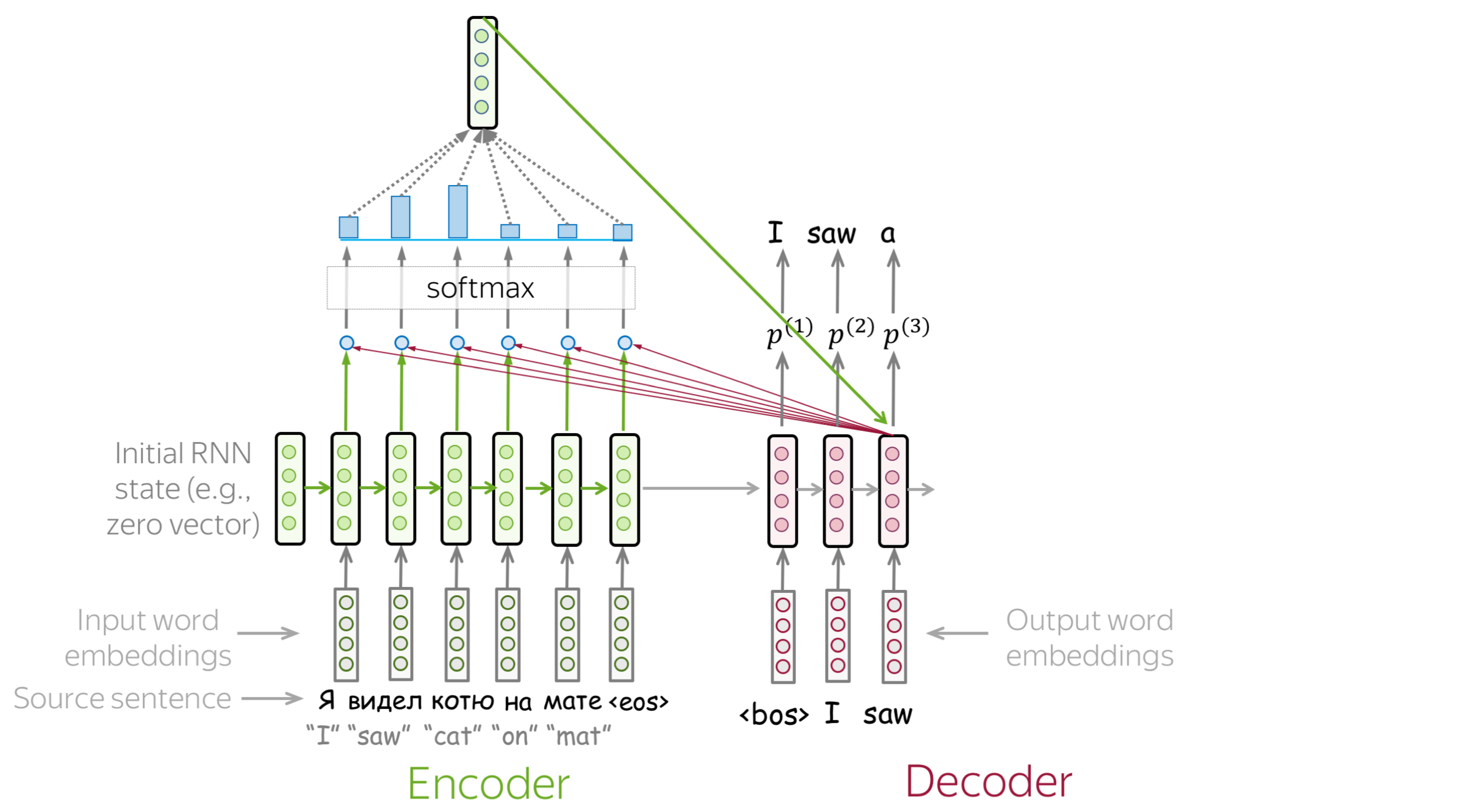
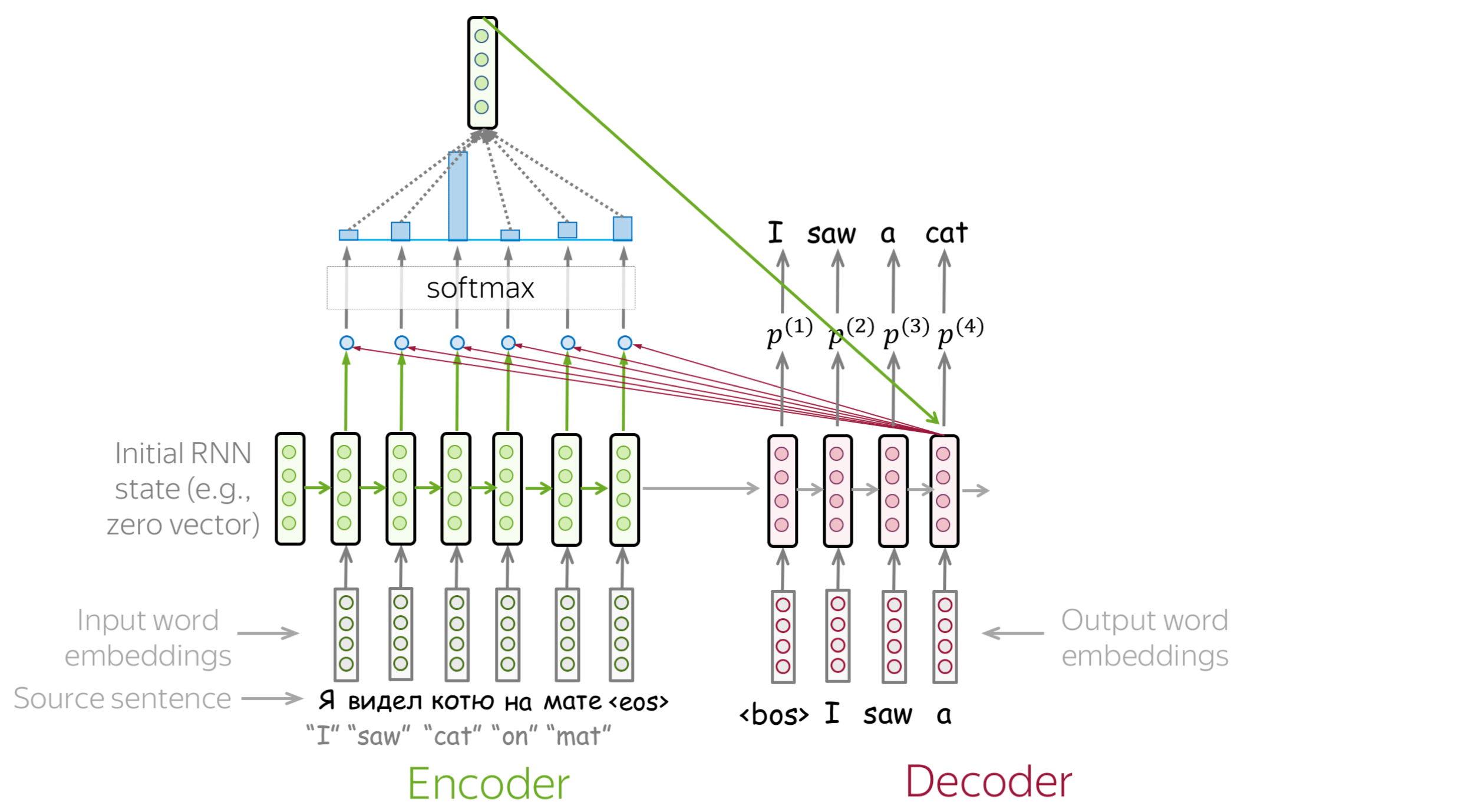
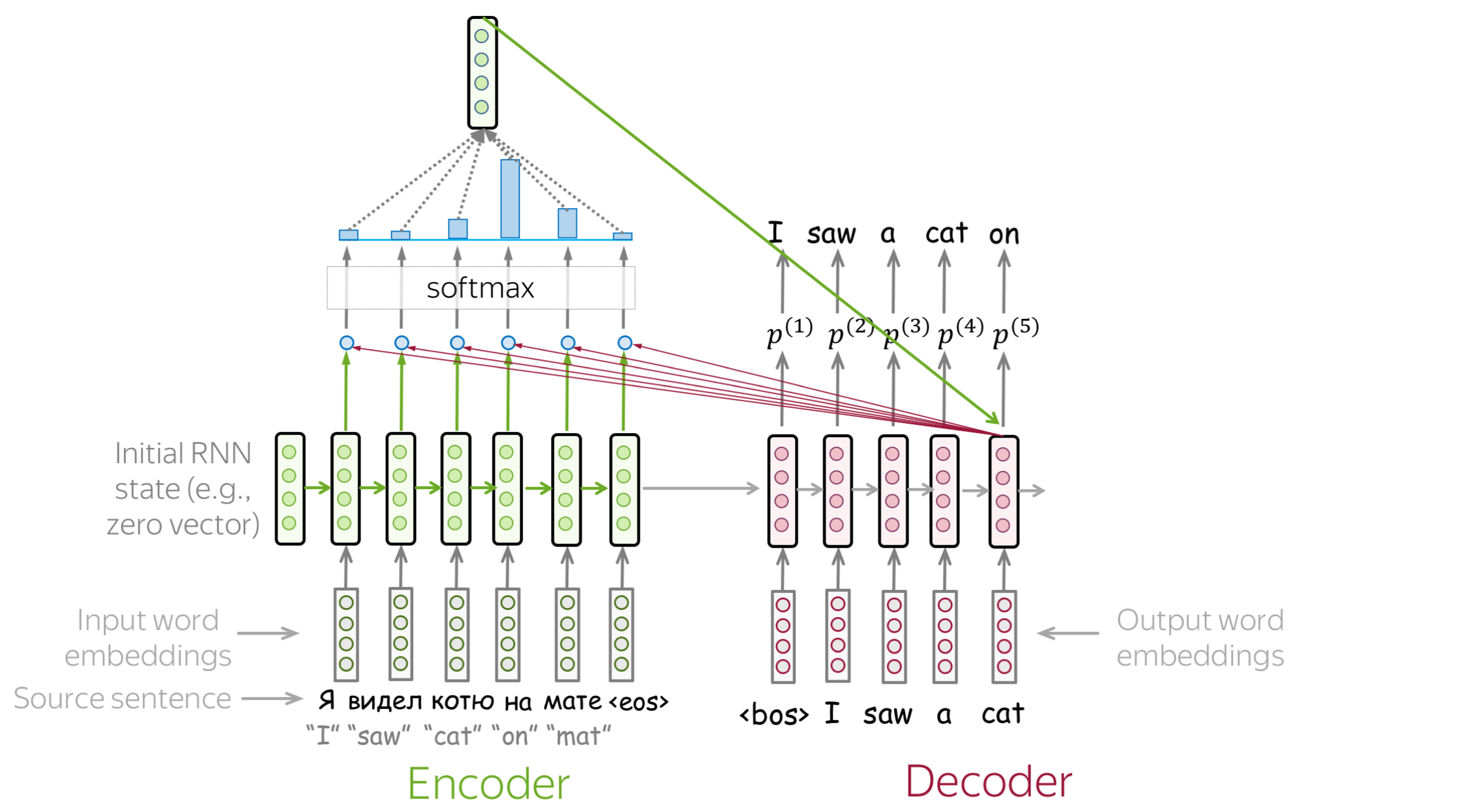
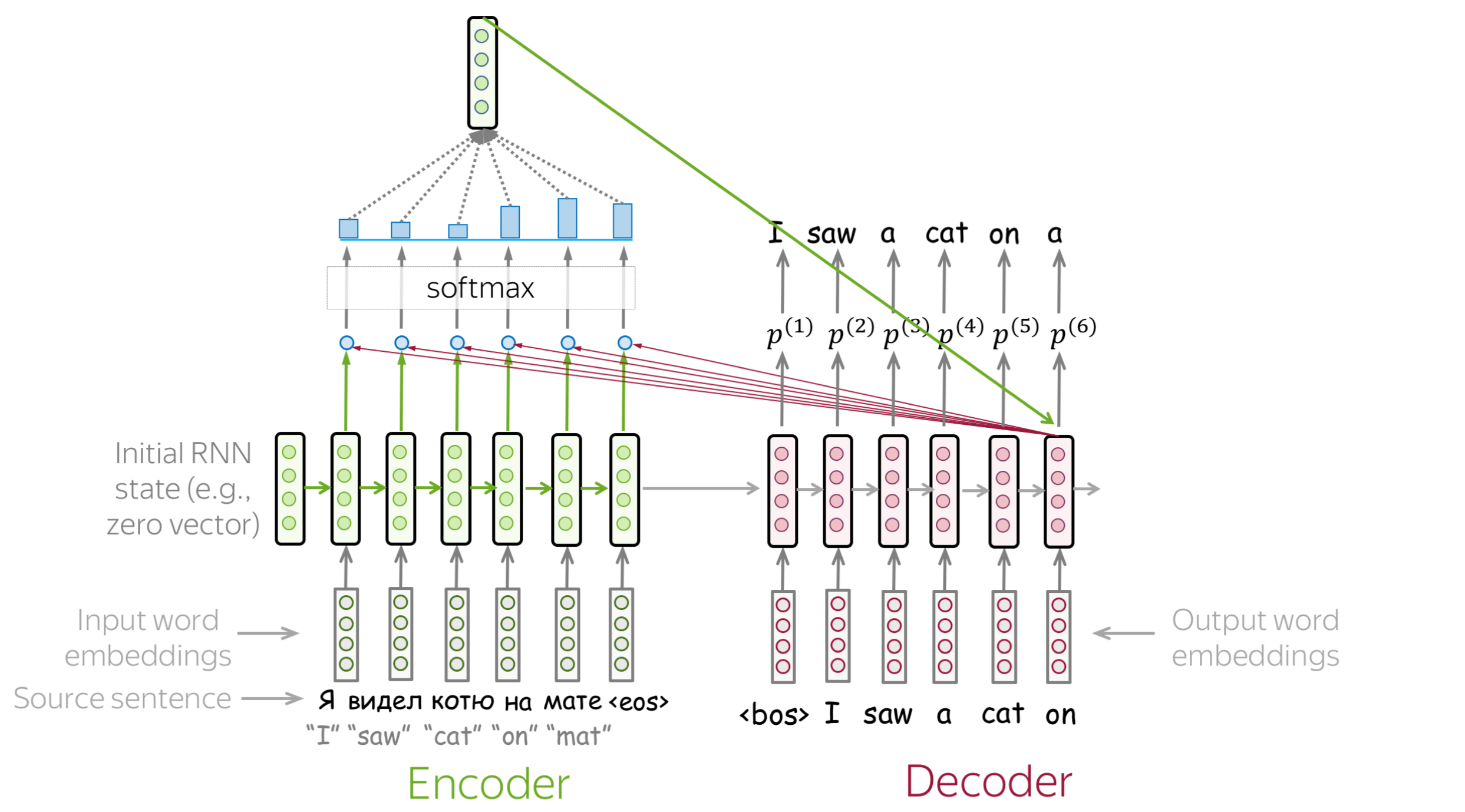
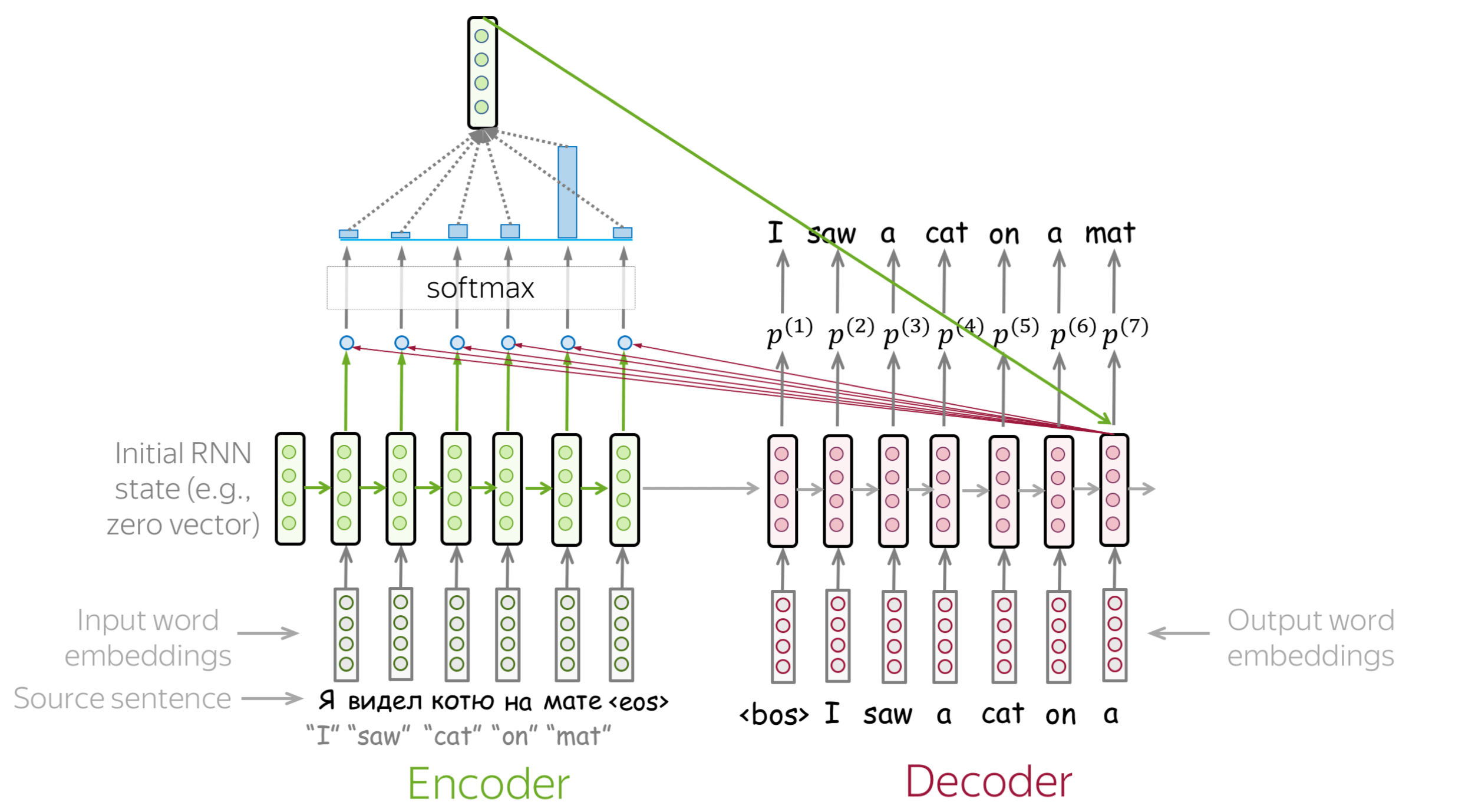
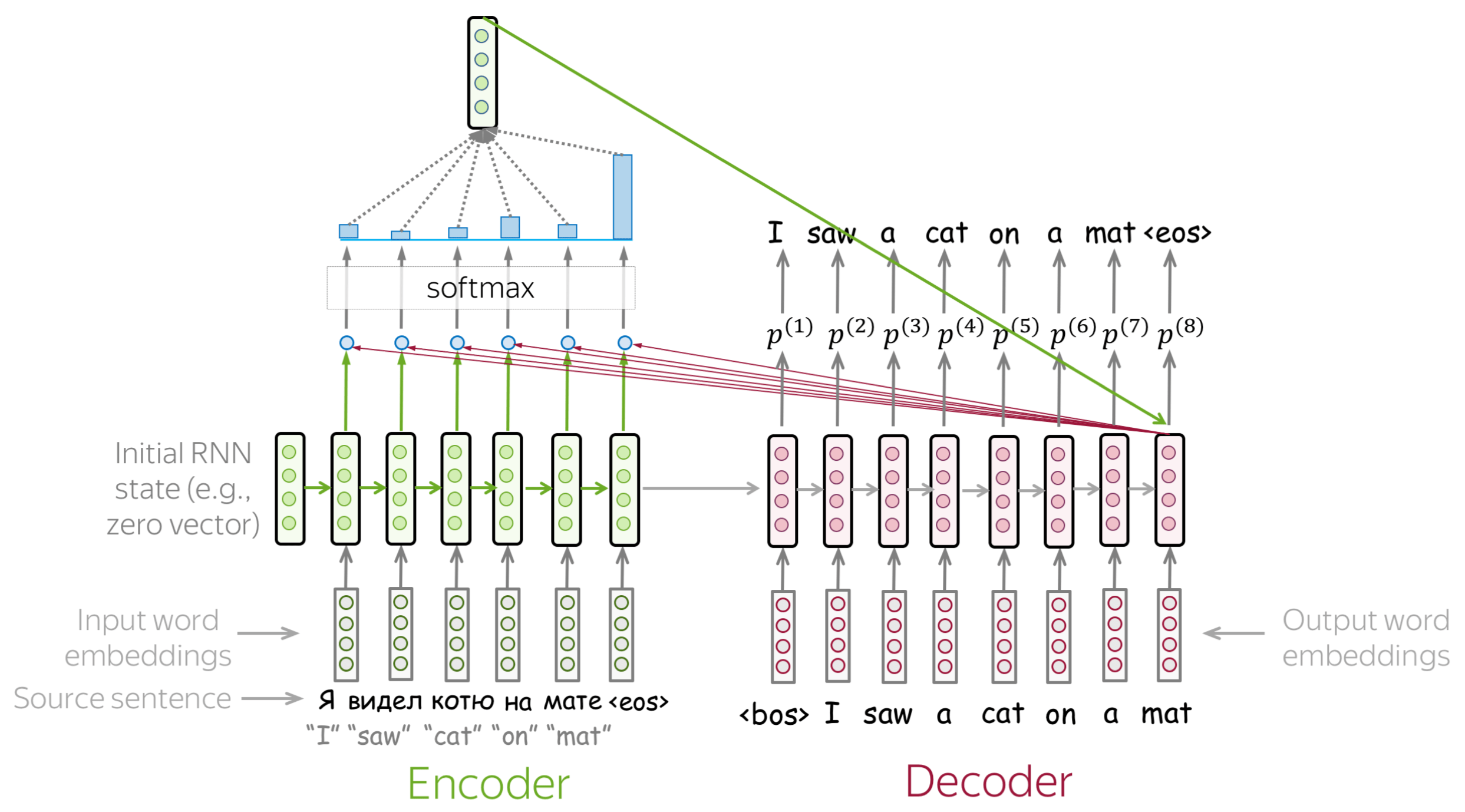
Attention addresses the fixed representation problem. At different steps, let a model “focus” on different parts of the input. An attention mechanism is a part of a neural network. At each decoder step, it decides which source parts are more important.
Move past RNNs (they’re so 2010s!)
- The Transformer model was introduced to address the limitations of RNNs (computational and otherwise).
- It uses the self-attention mechanism to capture dependencies between words in a sentence.
- This is the basis of today’s LLMs such as GPT and Claude.
The Transformer model (1/3)
| RNNs | Transformers | |
|---|---|---|
| Processing | Sequential (O(N) complexity) | Parallel |
| Dependencies | Struggles with long-term (vanishing gradient problem) |
Excels at long-range capture (self-attention mechanism) |
| Training | Limited parallelization | Highly parallelizable |
| Scalability | Difficult to scale | Highly scalable |
| Resource need | Less memory intensive but demanding computation for long sequences | Higher memory usage but more efficient computation |
| Application | Effective to process shorter sequences for specific tasks, and real-time processing | Better for complex NLP tasks (translation, comprehension) |
The Transformer model (2/3)
![]()
![]()
The Transformer model (3/3)
From self-attention to multi-head attention…
Syntactic heads: One of many heads
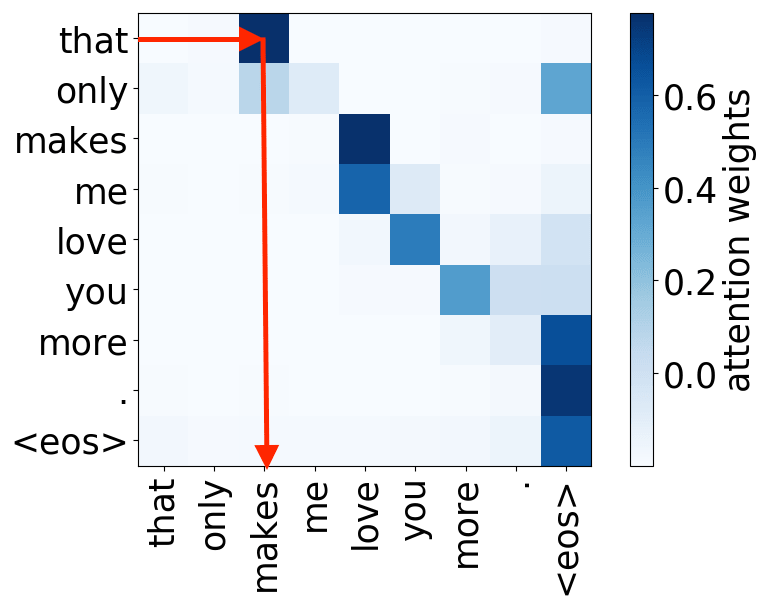
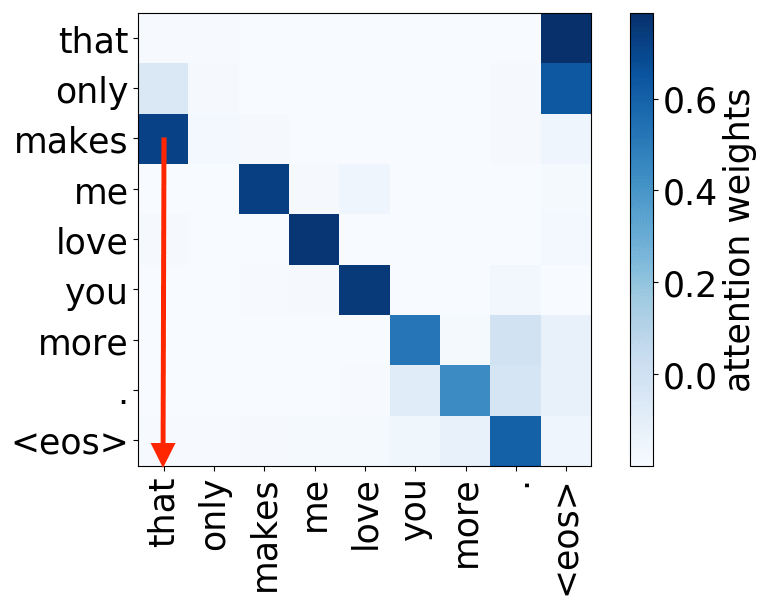
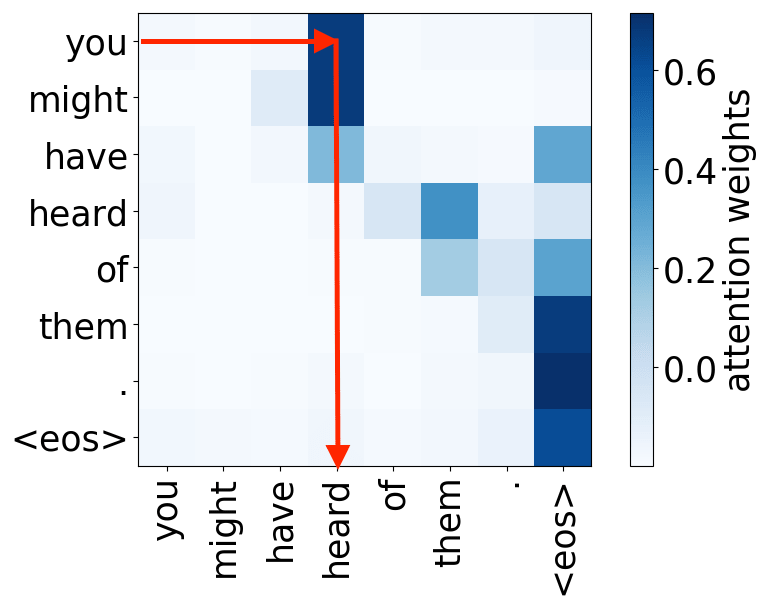
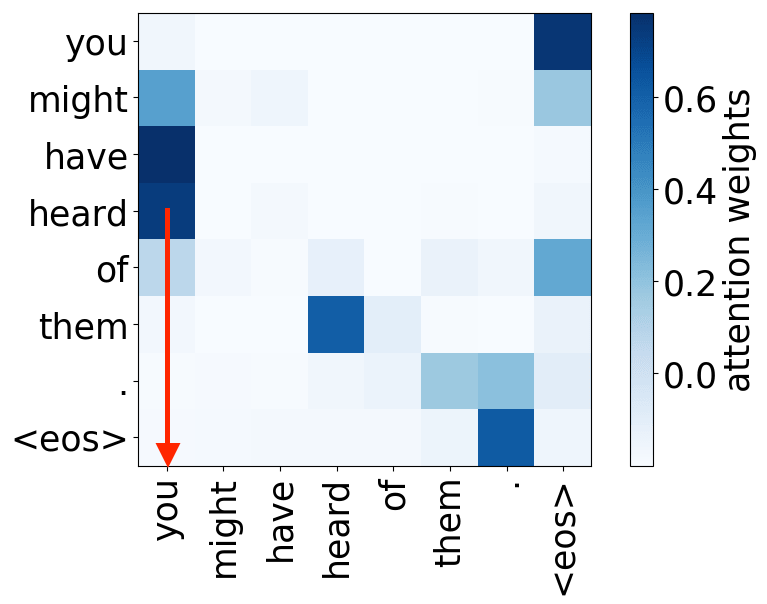
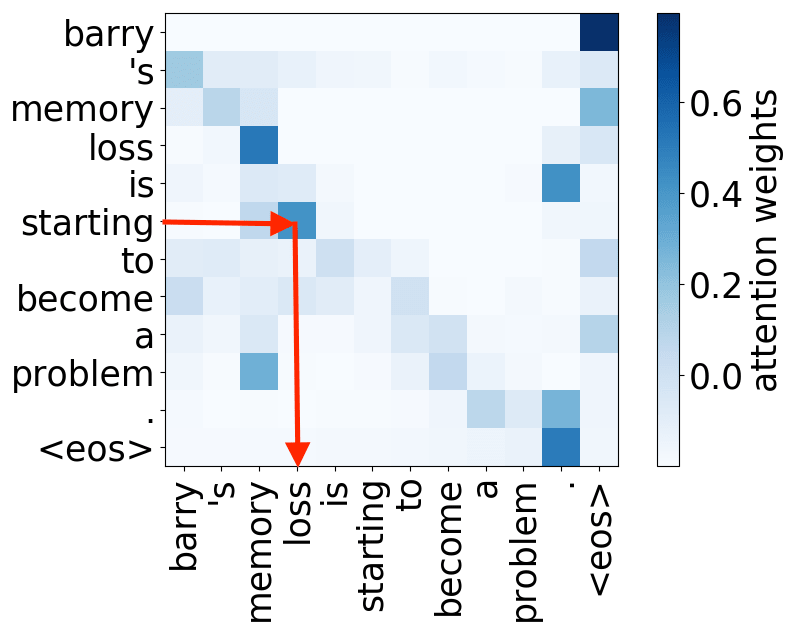
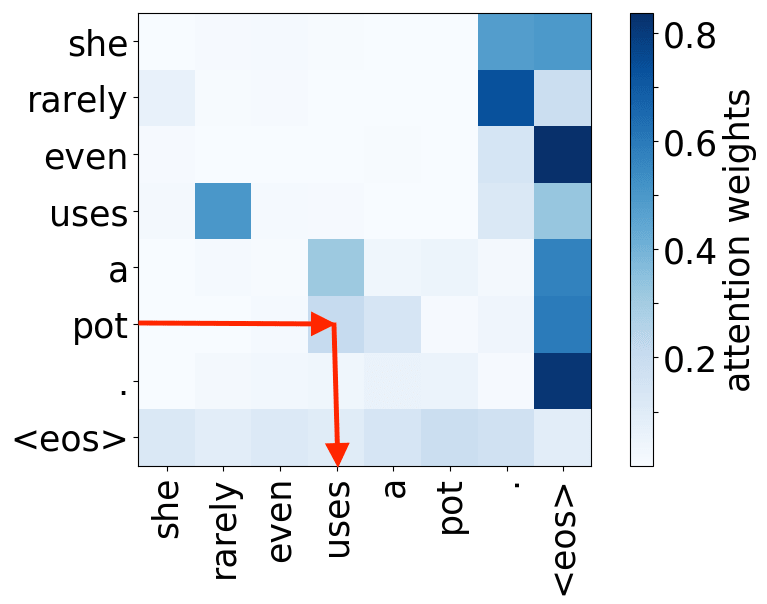
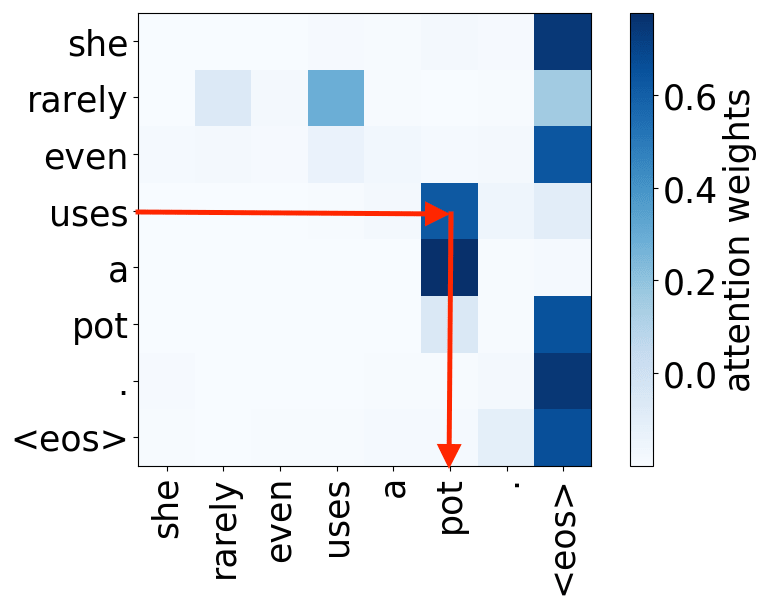
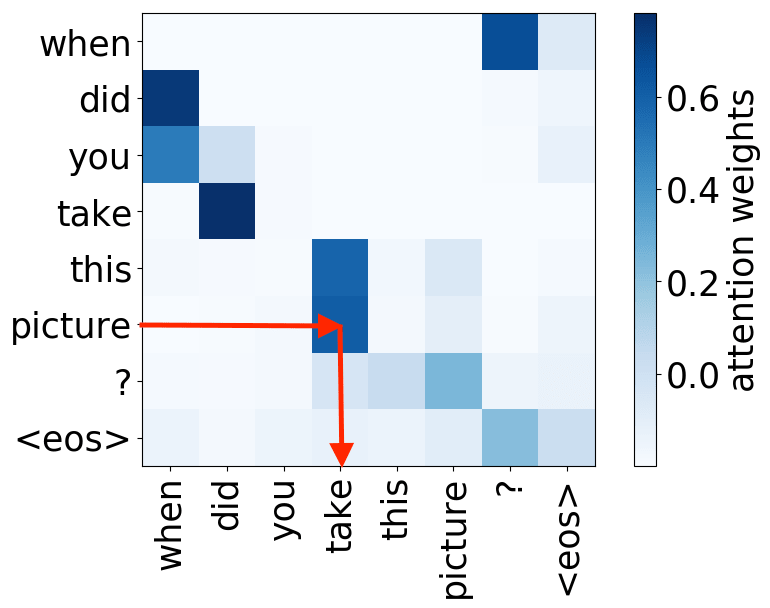
So far omitted: Encoder-decoder pair
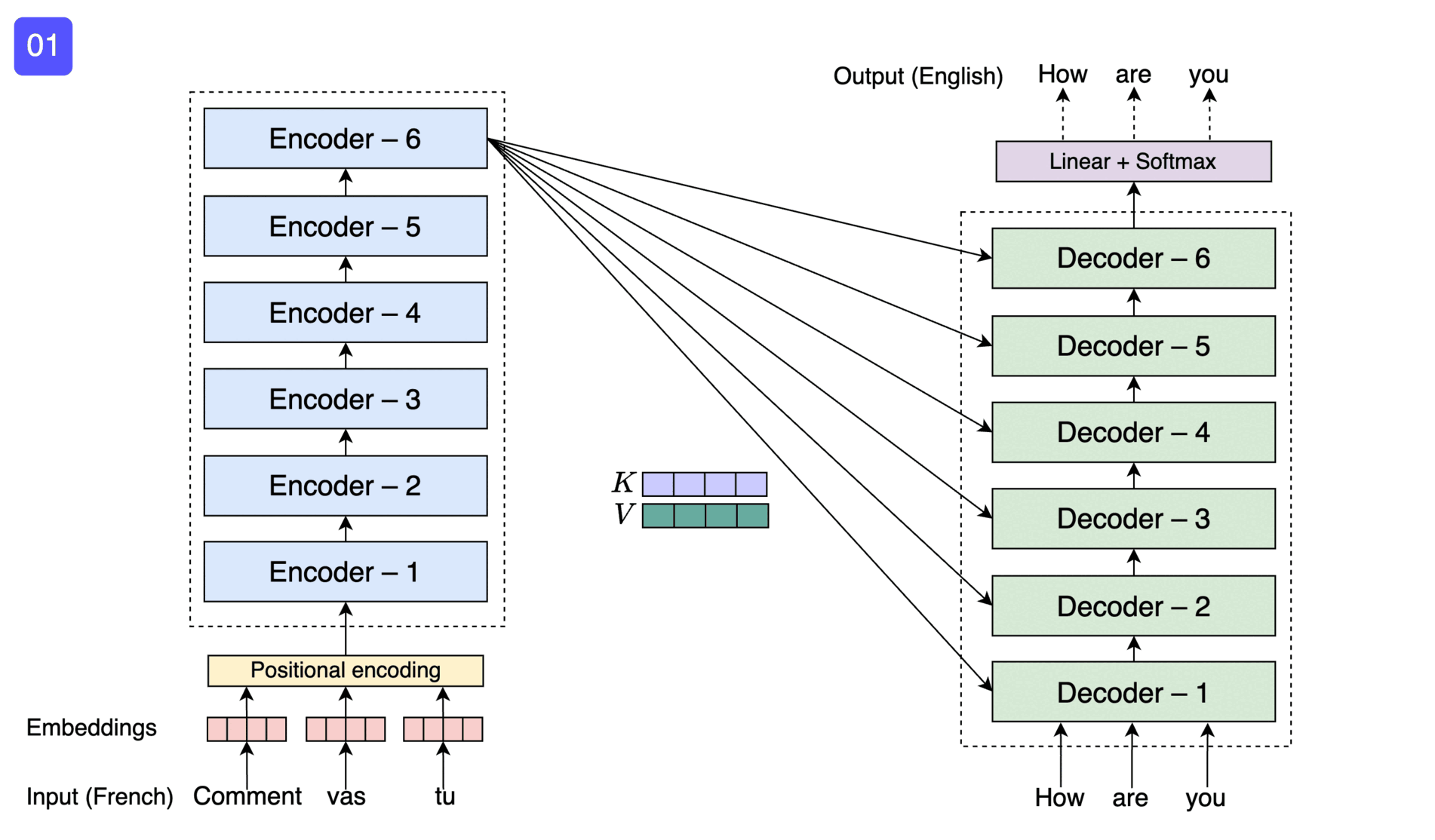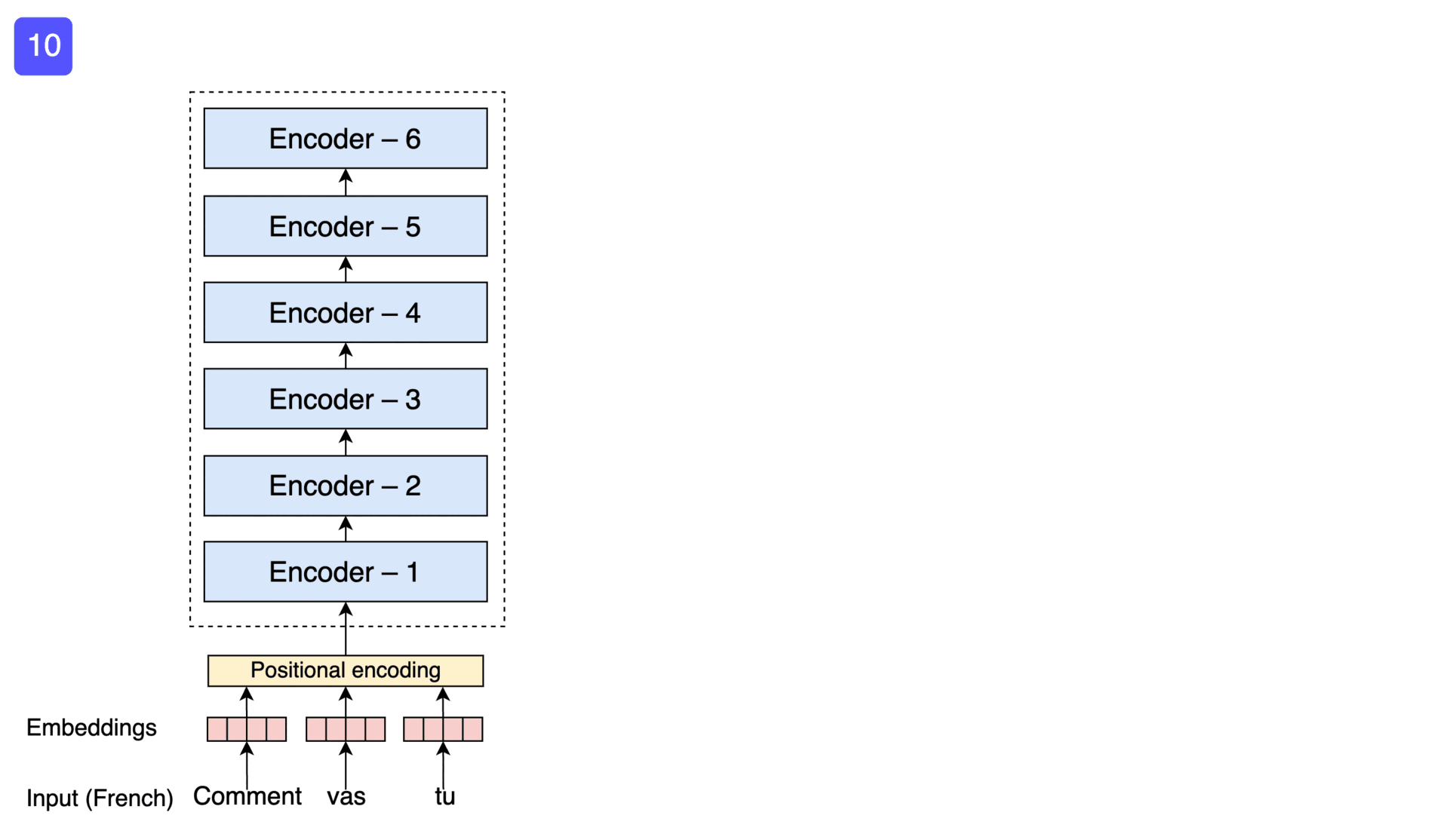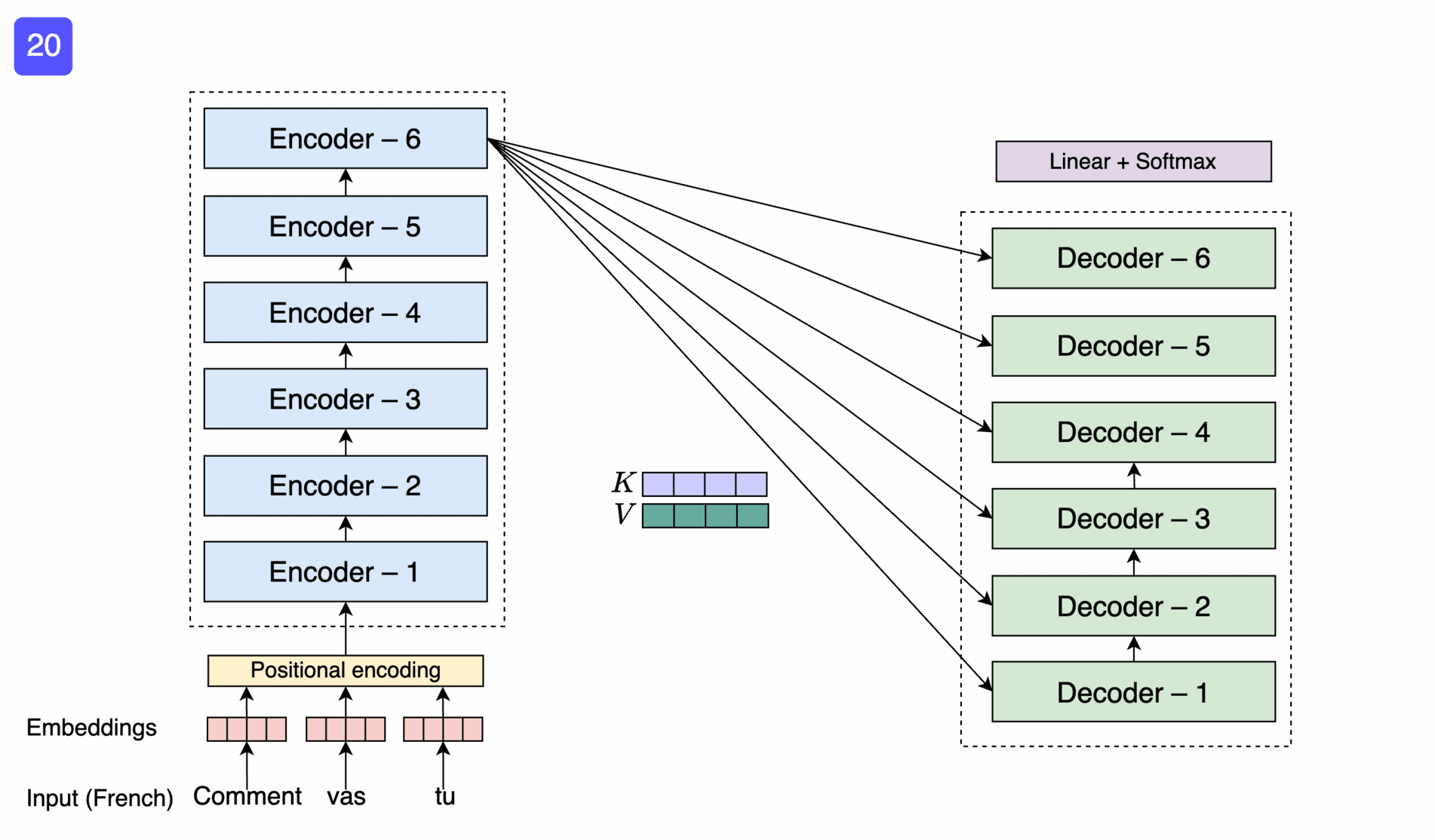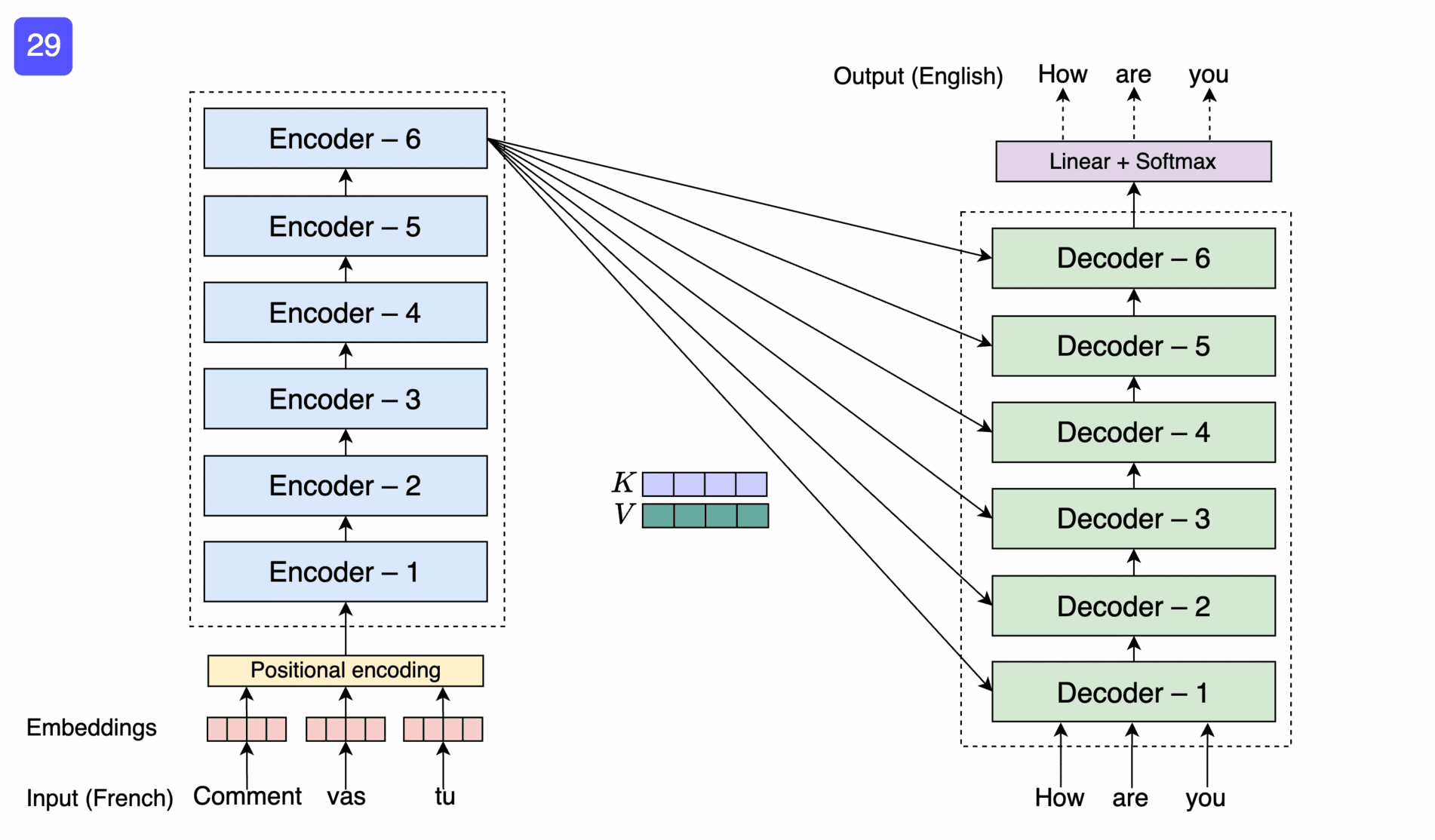
Figure 12: Educative, Inc. - “What are transformers?”
The Transformer Architecture
Figure 13: Lena Voita - “Sequence to Sequence (seq2seq) and Attention”
While a picture simplifies the Transformer, its true complexity lies in its operation. Google Research has a notebook for language translation to test the following transformer: ![]()
Next up: GPT - Generative Pre-trained Transformer
The latest and greatest

Figure 14: Microsoft Research - “How Large Language Models work”
Transformer in action (1/2)
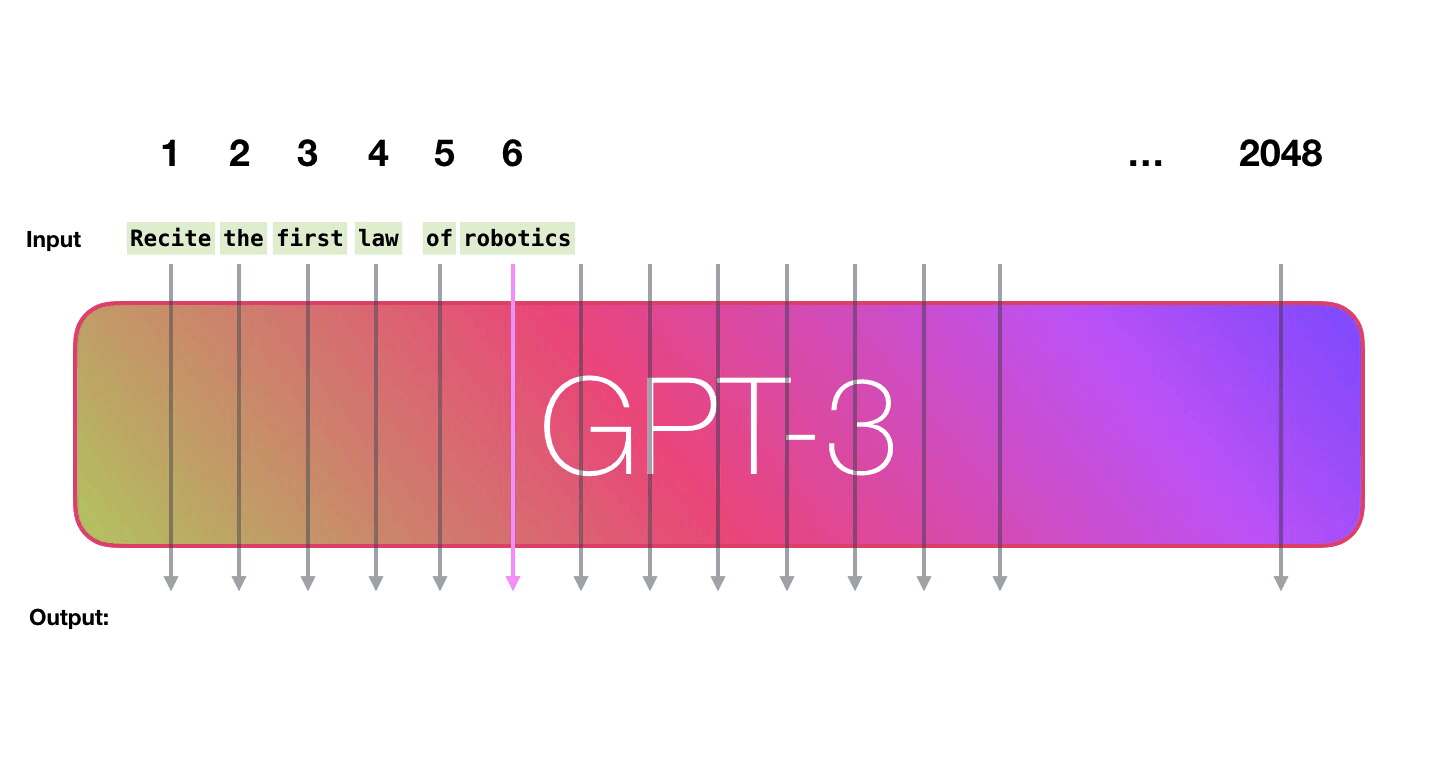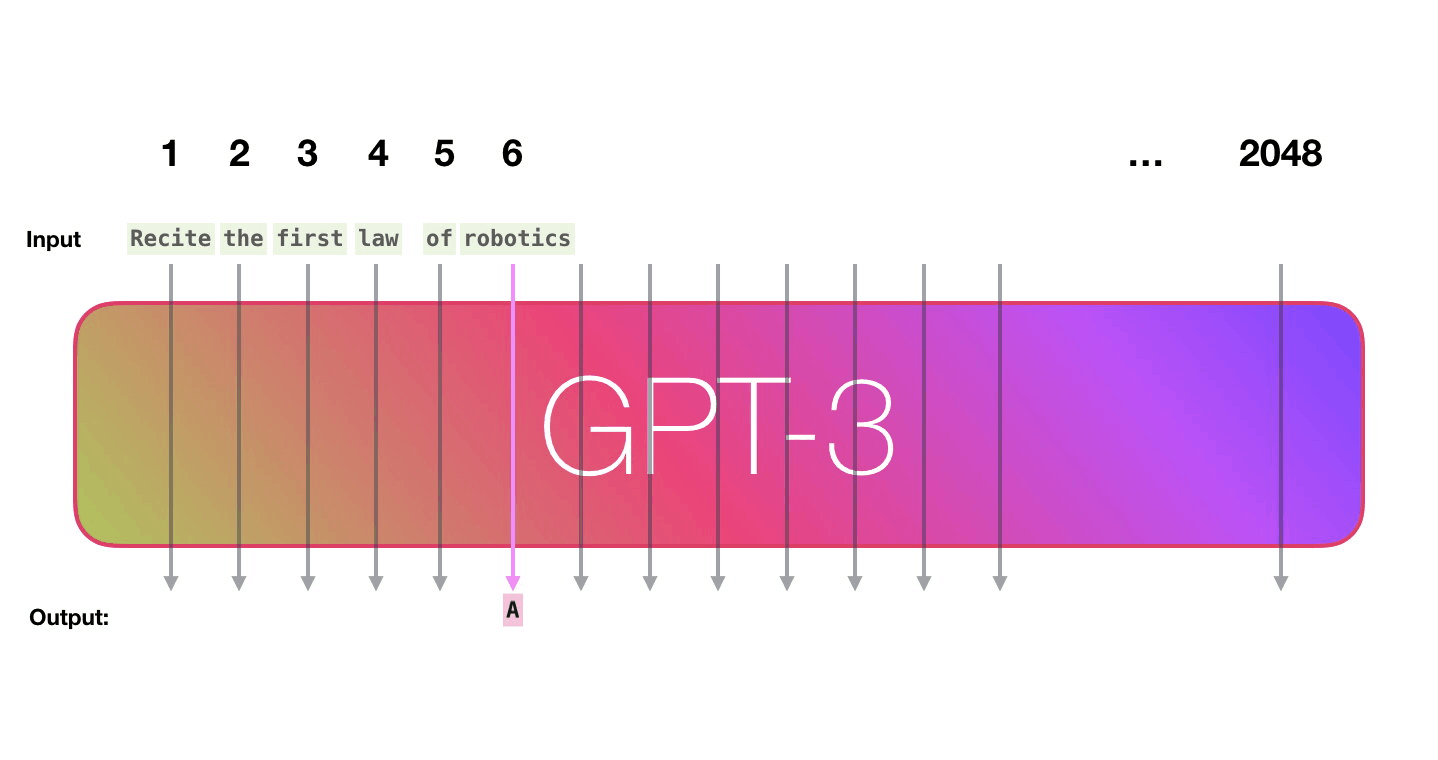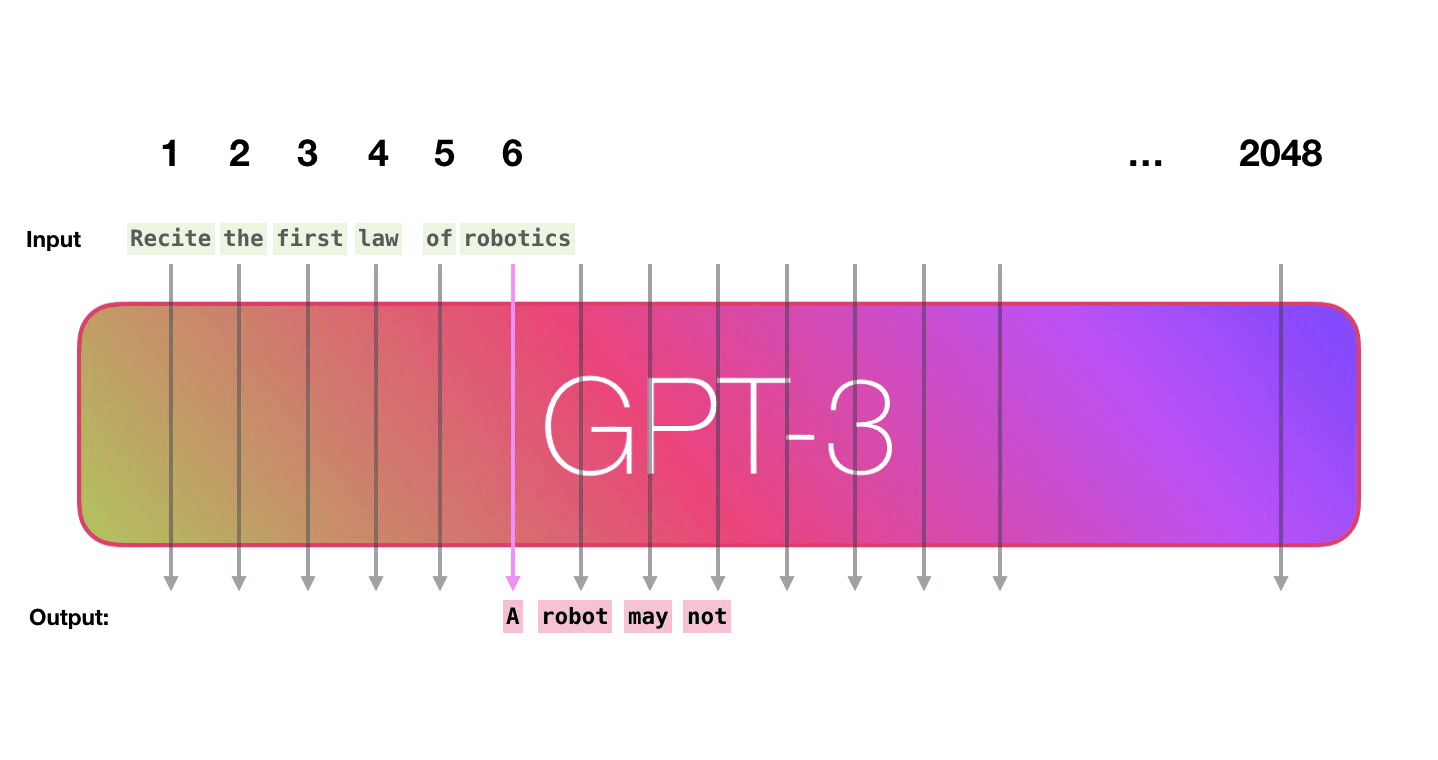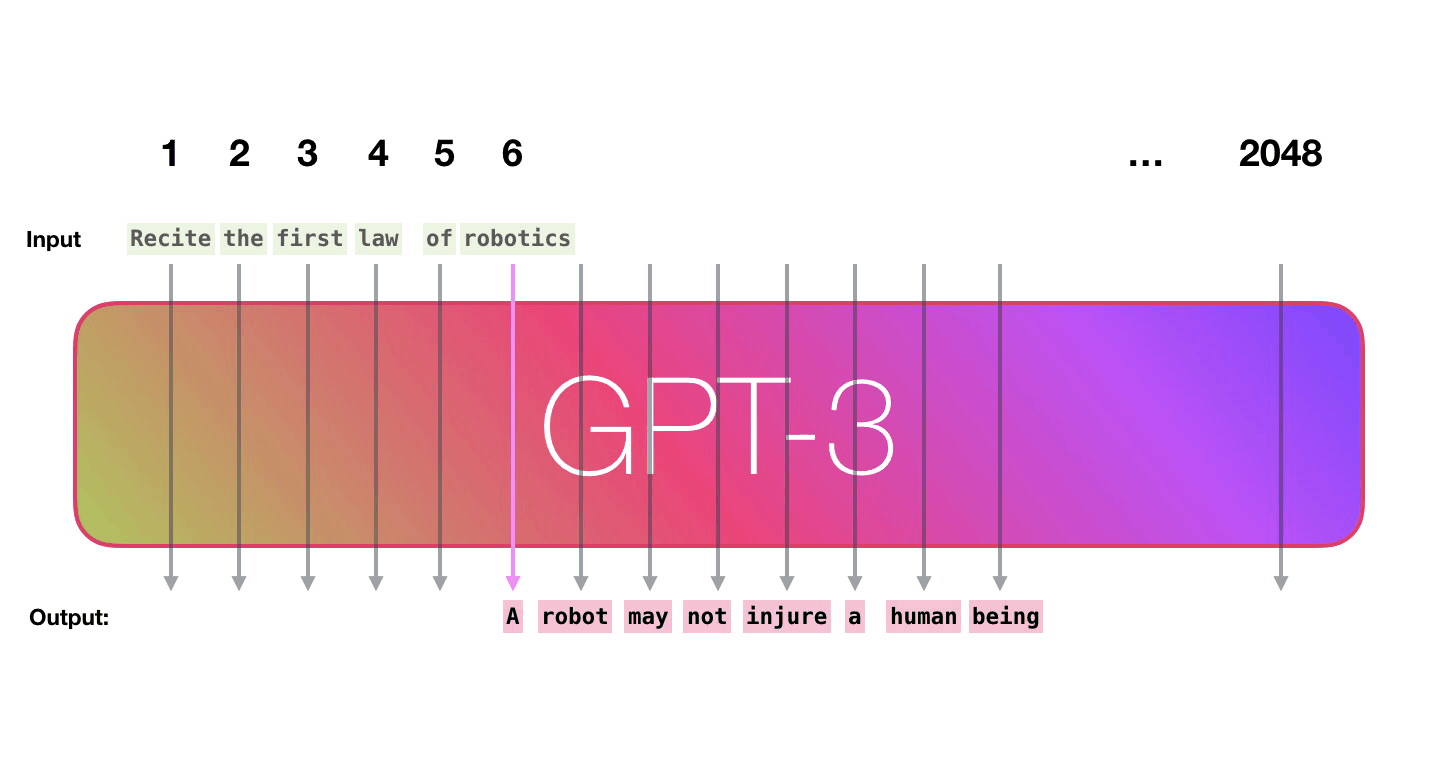
Figure 15: Jay Alammar - “How GPT3 Works - Visualizations and Animations”
Transformer in action (2/2)
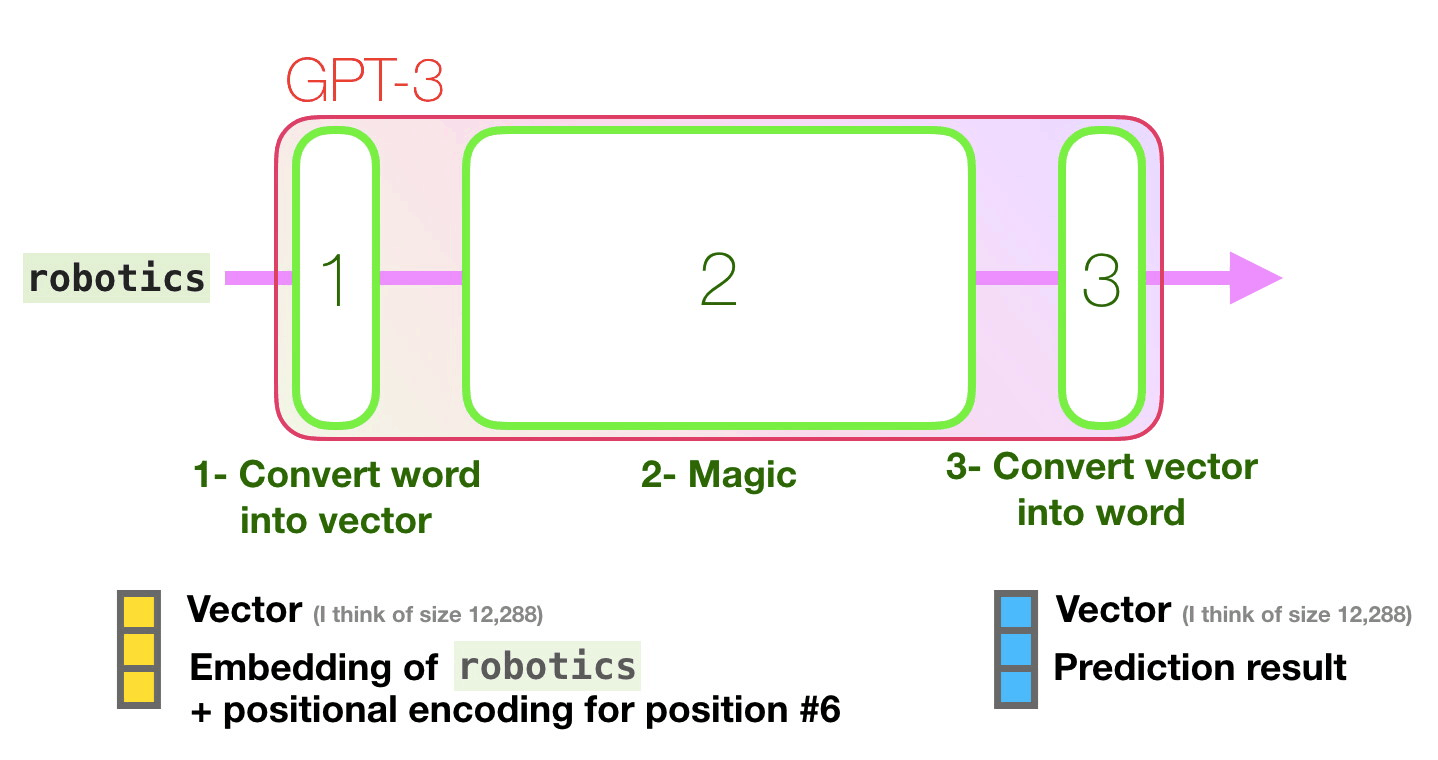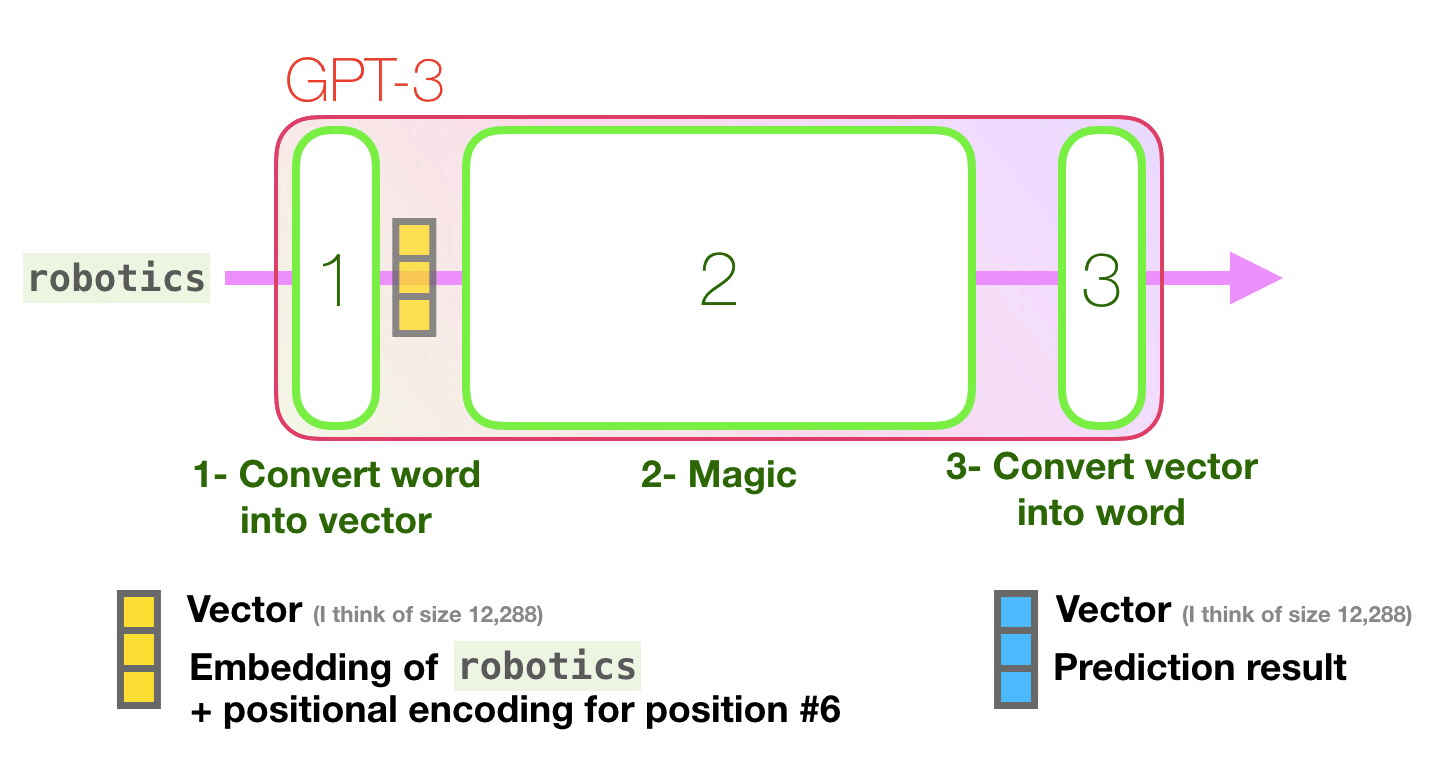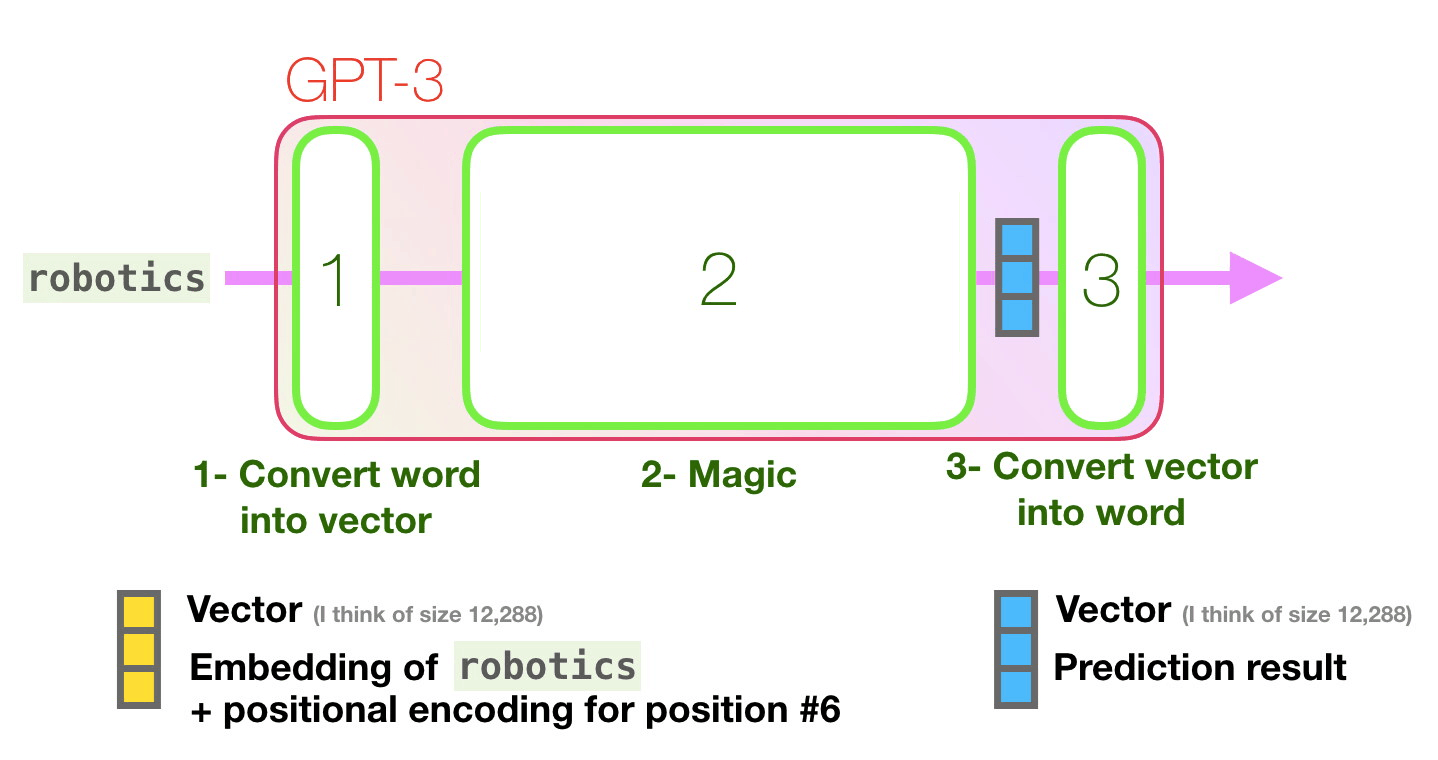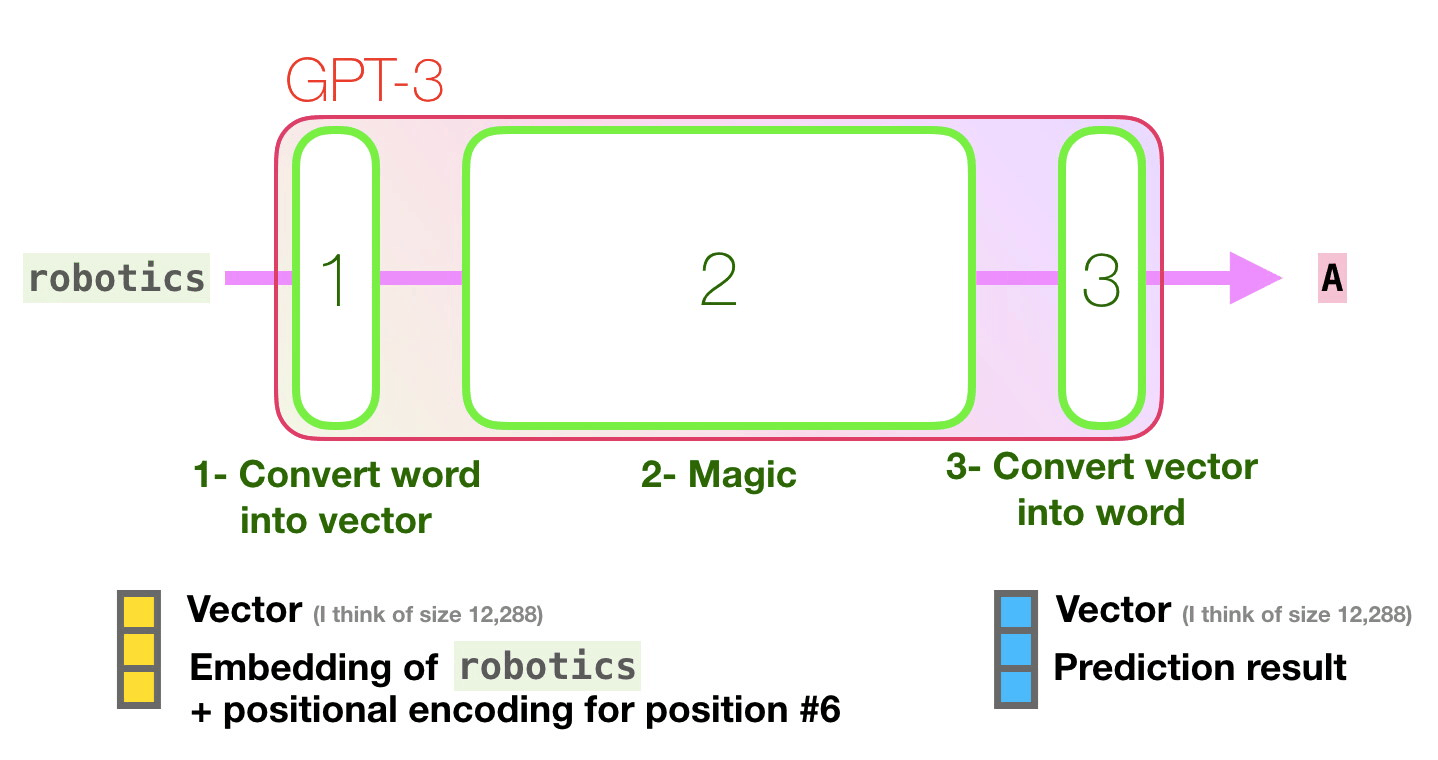
Figure 16: Jay Alammar - “How GPT3 Works - Visualizations and Animations”
The Transformer
![]()
![]()
![]()
![]()
Parallel processing is key
Figure 17: Google Research - “Transformer: A Novel Neural Network Architecture for Language Understanding”
Back to the Transformer
![]()
![]()
![]()
![]()
![]()
Revisiting multi-head attention (1/2)
Syntactic heads: One of many heads!
Revisiting multi-head attention (2/2)
Why is attention so important?
![]()
![]()
Types of prompting



Varying performance by prompt type
Example using MMLU (Massive Multitask Lang. Understanding):
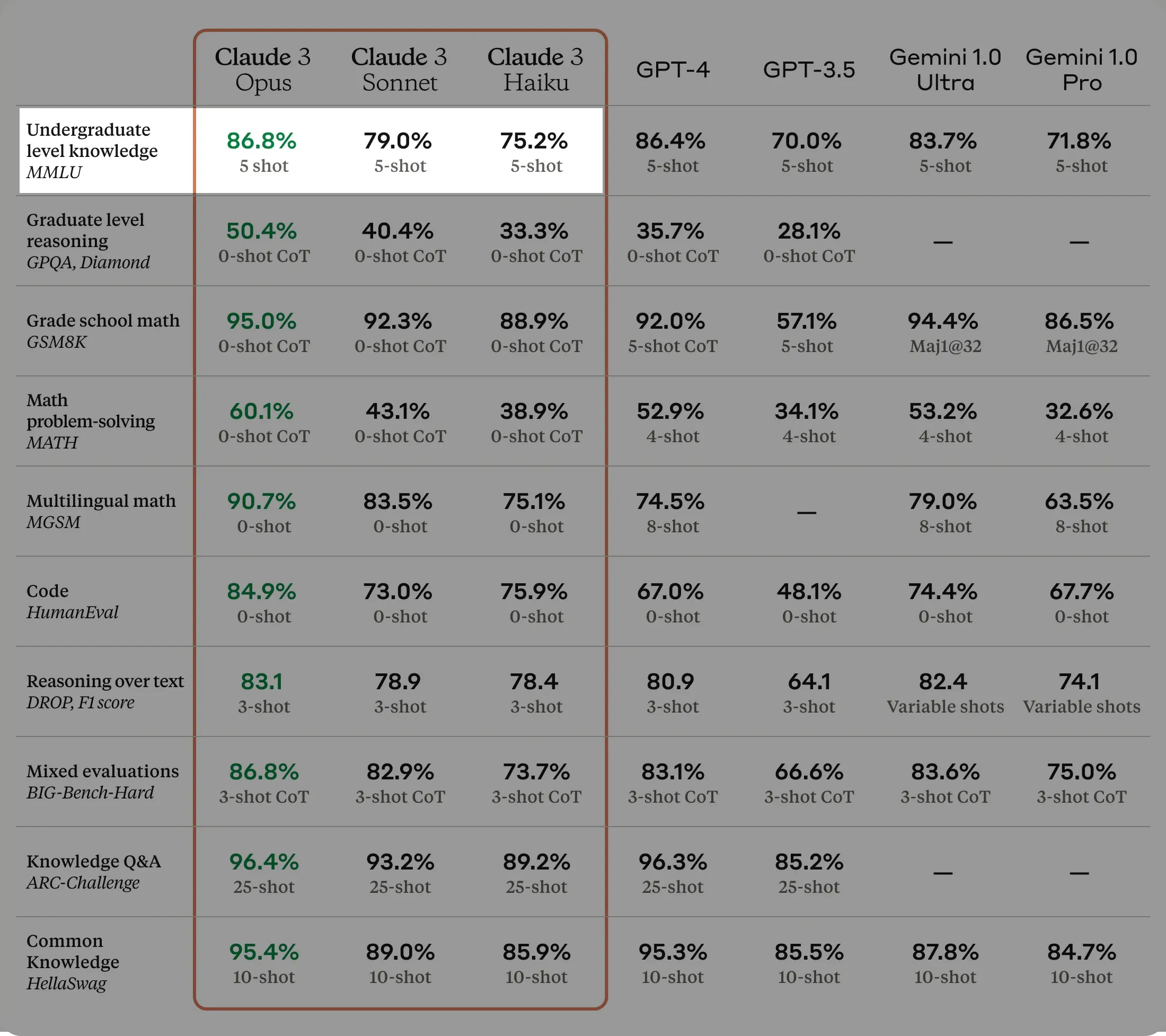
Figure 19: Anthropic - “Introducing Claude 3”
7 months later (October 22, 2024)
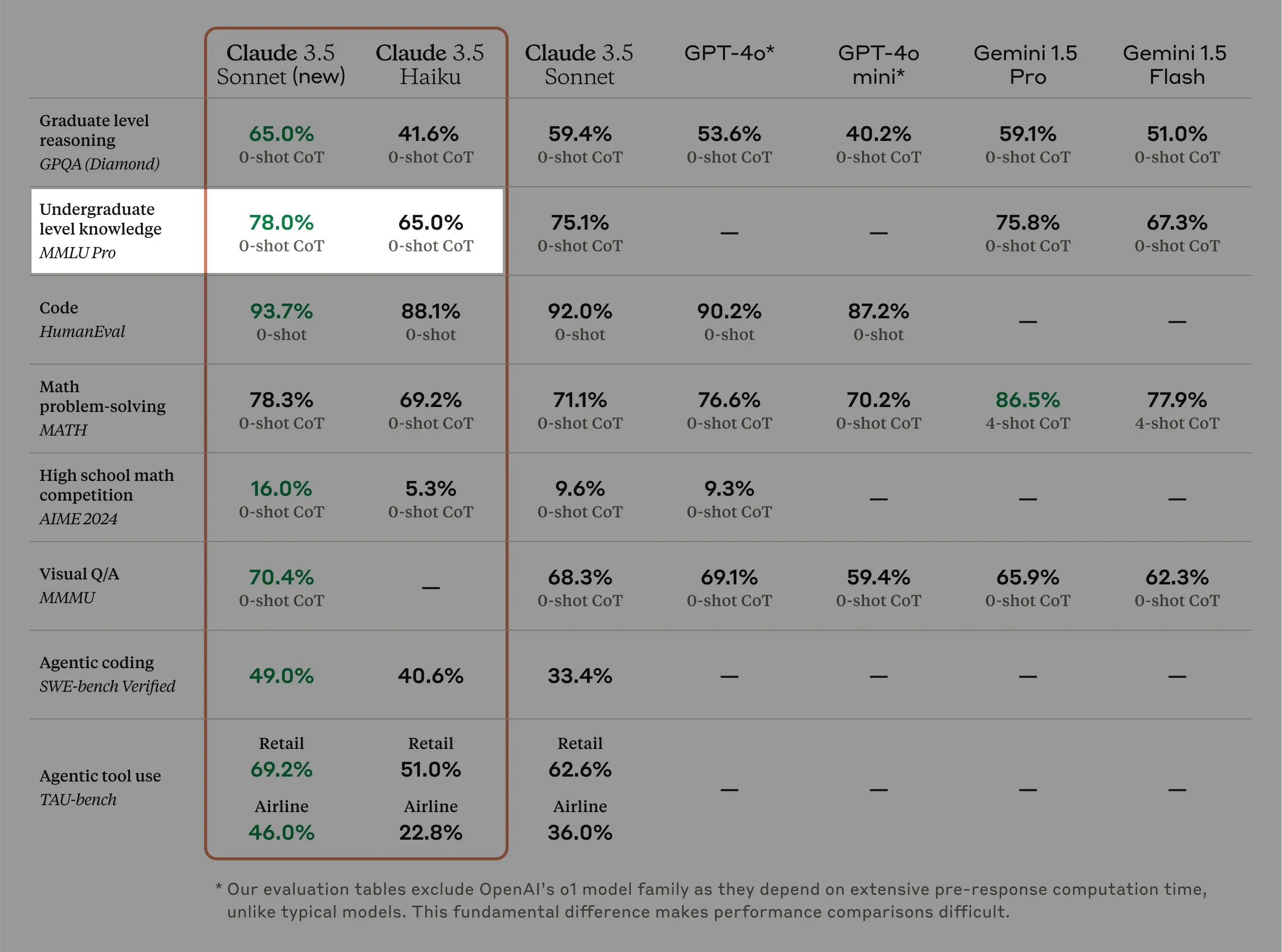
Figure 20: Anthropic - “Introducing Claude 3.5”
After another seven months (May 22, 2025), agentic tasks take center stage
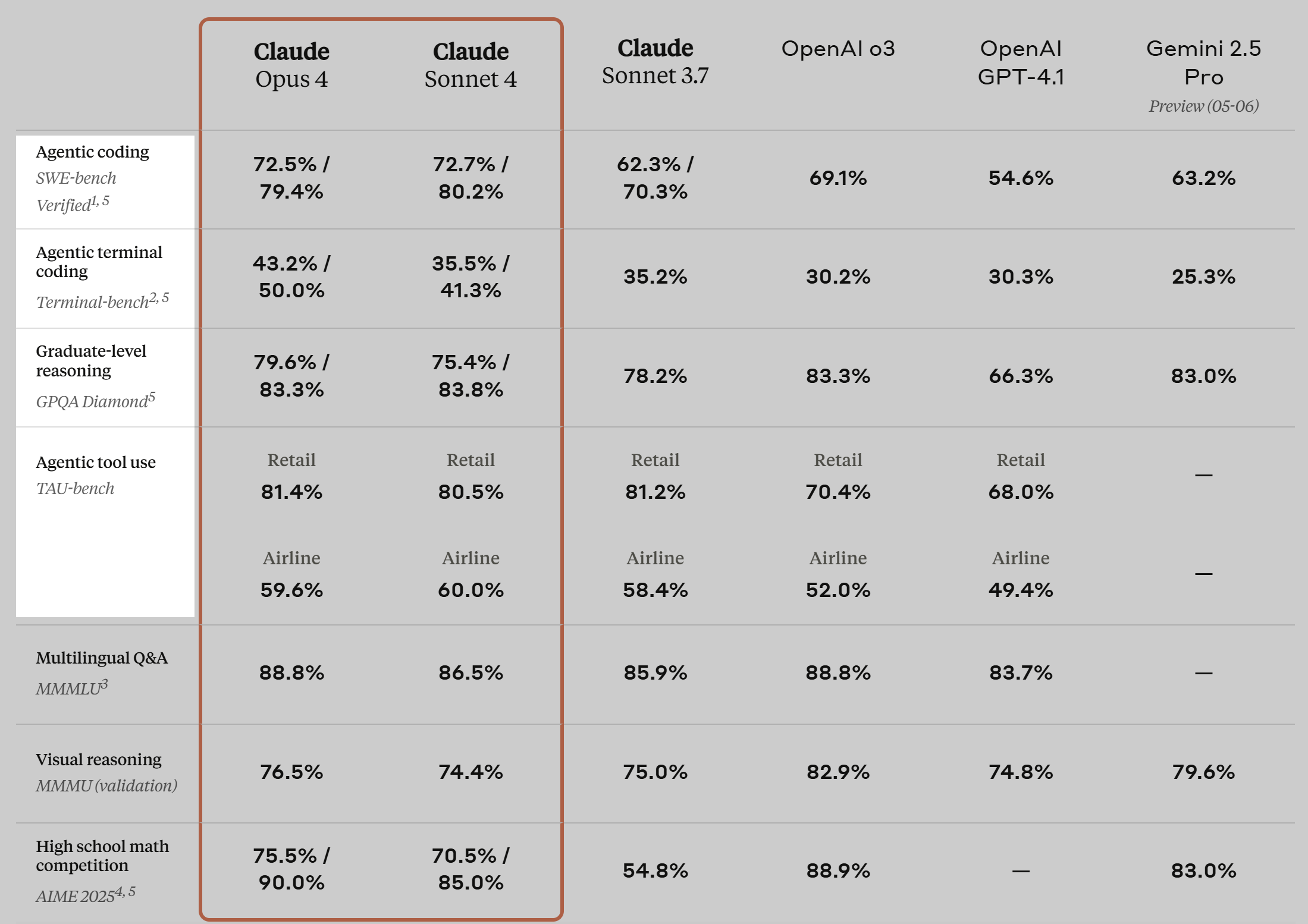
Figure 21: Anthropic - “Introducing Claude 4”
An agent
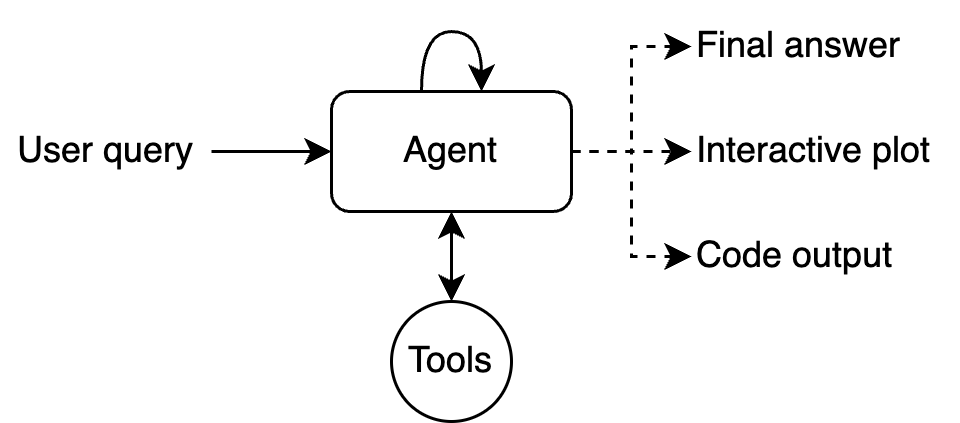
Figure 22: André Ferreira and Telmo Felgueira - “Building a Better AI Agent with Claude”
An agentic workflow
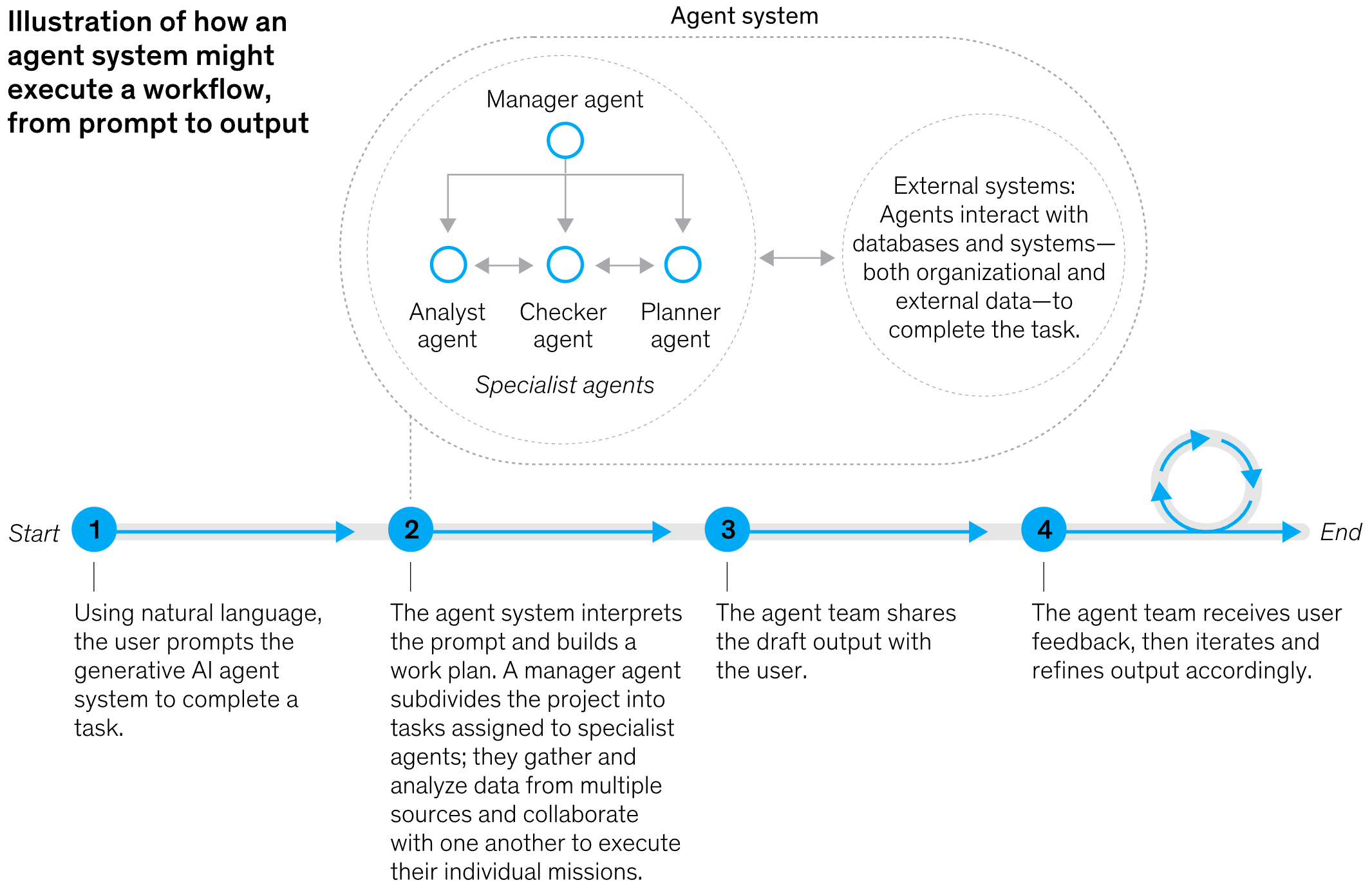
Figure 23: McKinsey - “Why agents are the next frontier of generative AI”
Phases of GPT’s training (1/2)

Phases of GPT’s training (2/2)
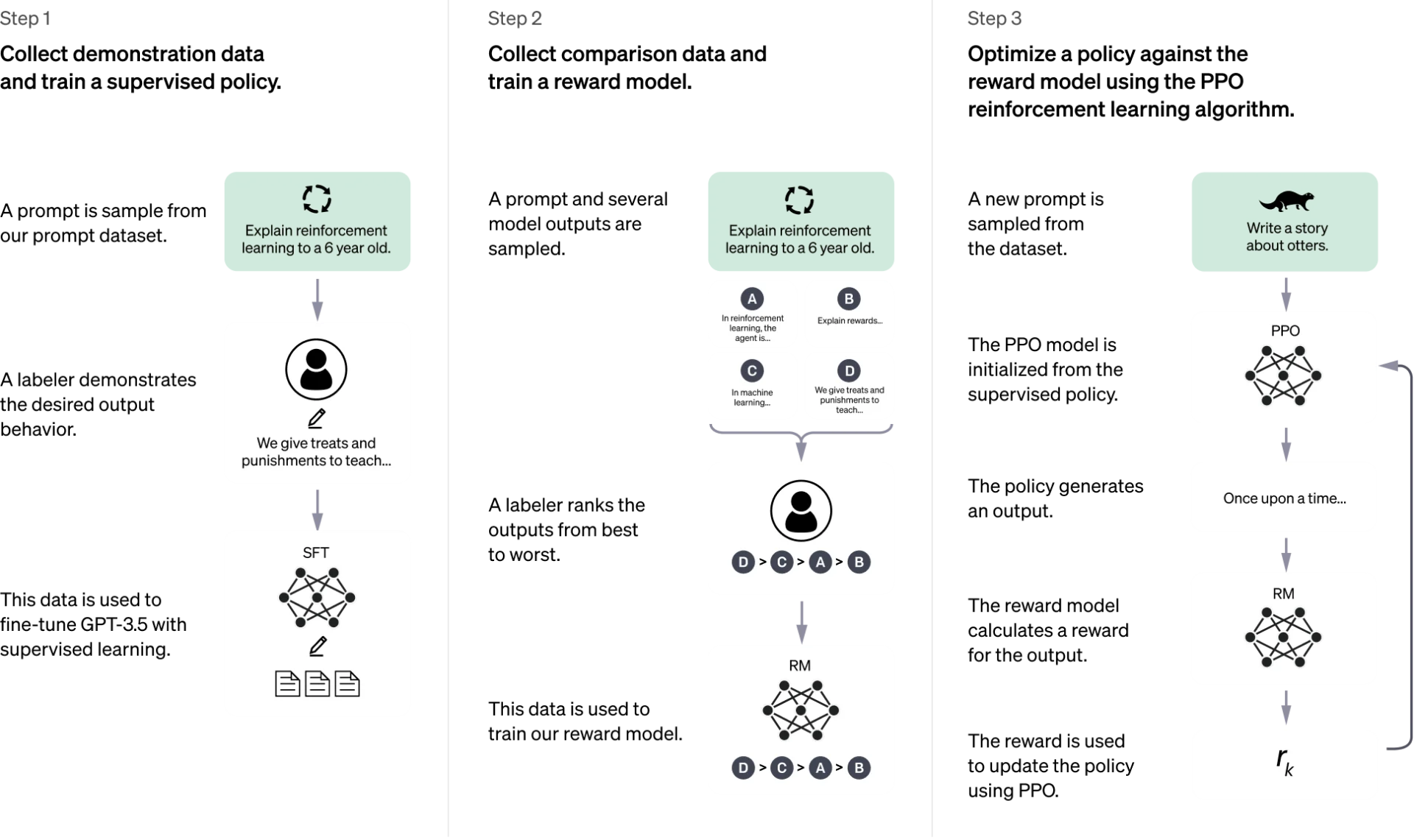
Figure 25: OpenAI - “Introducing ChatGPT”
Footnotes
By Claude Sonnet 4’s count on VS Code.
Generated using Claude on Perplexity.
Generated using Claude on Perplexity.
Generated using Claude on Perplexity.